前几天就已经看到港大的:

MiniRAG框架了
没认真仔细看,看介绍知道了,这就是专门给中小型模型、端侧技术准备的RAG技术
然后周四的时候,看到了主动检索增强agent技术的时候,发现了图RAG技术的一个nano实现,即:nano_graphrag库
这个库,安装的不是很顺利,因为安装风格竟然是:pip install -e .
弄得我很懵逼,即使在venv环境下,还是报错
沮丧,python这边的包报错,往往都很灵性
暂时搁置了一下,晚上试图安装Meta的时候,又是包报错,都无语了,跑到人家VideoRAG群里,抱怨了几句,结果发现VideoRAG的实现竟又是使用了conda的,所以估计完全没问题
对高效且轻量级的检索增强生成(RAG)系统日益增长的需求,凸显了在现有RAG框架中部署小型语言模型(SLMs)时所面临的重大挑战。
由于SLMs在语义理解和文本处理能力上的局限性,当前方法面临严重的性能下降问题,这在资源受限的场景中阻碍了其广泛应用。
为了应对这些根本性限制,我们提出了MiniRAG,这是一种专为极简和高效而设计的新型RAG系统。
MiniRAG引入了两项关键技术创新:
(1)一种语义感知的异构图索引机制,将文本块和命名实体结合在一个统一结构中,减少了对复杂语义理解的依赖;
(2)一种轻量级的拓扑增强检索方法,利用图结构实现高效的知识发现,而无需高级语言能力。我们的大量实验表明,
MiniRAG在使用SLMs时,性能与基于LLM的方法相当,同时仅需25%的存储空间。
此外,我们还贡献了一个全面的基准数据集LiHua-World,用于评估轻量级RAG系统在现实设备场景下处理复杂查询的能力。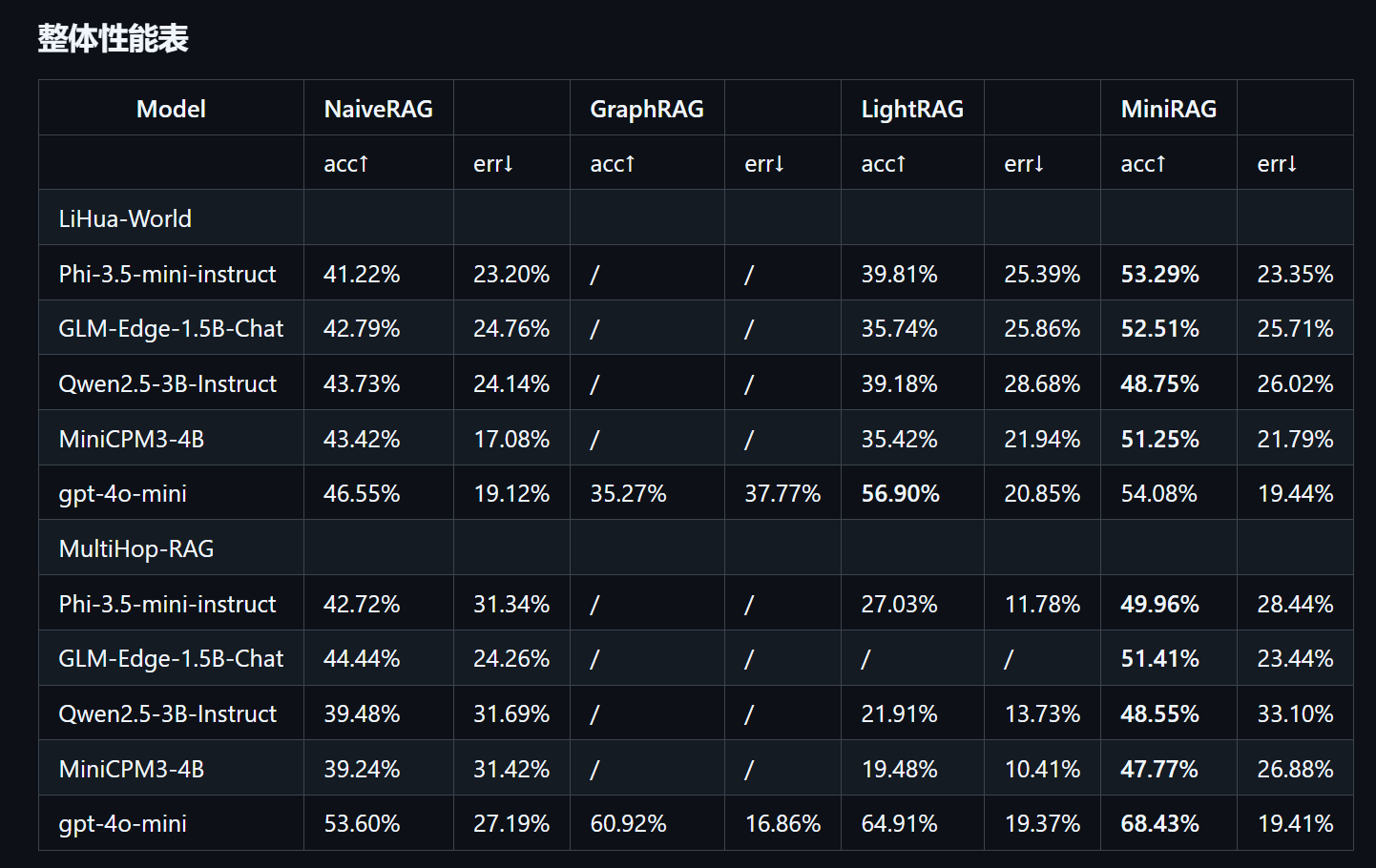
看了一下MiniRAG
主要的贡献点就是在测评集下,肯伊将小模型,注入Phi-3.5,1.5B的GLM和Qwen2.5-3B这类小模型,准确率提升不到10%左右吧
对比NaiveRAG吧
当然还是又贡献的
不能说人家没贡献;
======================================

不过更有趣的是它这个框架为了测评,所虚构的数据集
https://github.com/HKUDS/MiniRAG/blob/main/dataset/LiHua-World/README_CN.md
它里面有52周的记录
Time: 20260622_11:00
JenniferMoore: Hey Li Hua! Hope you're doing great! Could you please fill out a
quick survey about your experience with our training sessions so far?
Your feedback really helps me improve! 😊
LiHua: Hey Jennifer! Sure, I’ll fill out the survey. Thanks for checking in! 💪
JenniferMoore: Awesome! I appreciate it! Can't wait to hear what you think.
Keep pushing yourself! 😄
LiHua: Will do! Looking forward to our next session! 🎸
JenniferMoore: That's the spirit! See you on Tuesday at 10am for some
intense workout fun! 🤗💪
LiHua: I'm excited! Just finished some prep for our session. See you soon! 🌟
JenniferMoore: Perfect! You're always so dedicated. It’s going to be a great session! 随便打开一个文件,就是LiHua和某人的聊天记录
啊,行吧,这一看就是个合成数据
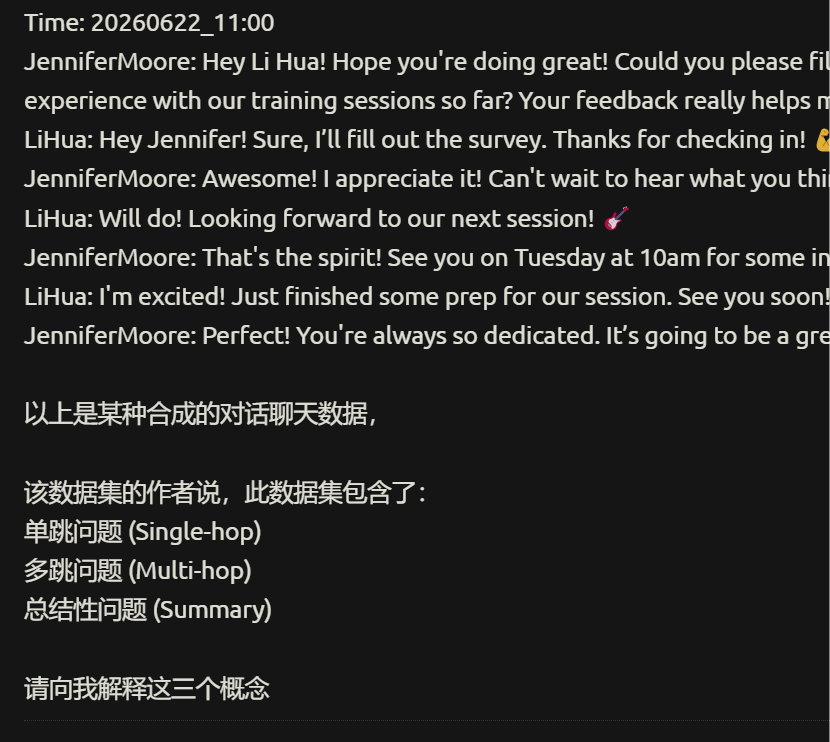
所以我让DS给我解释一下这三个概念
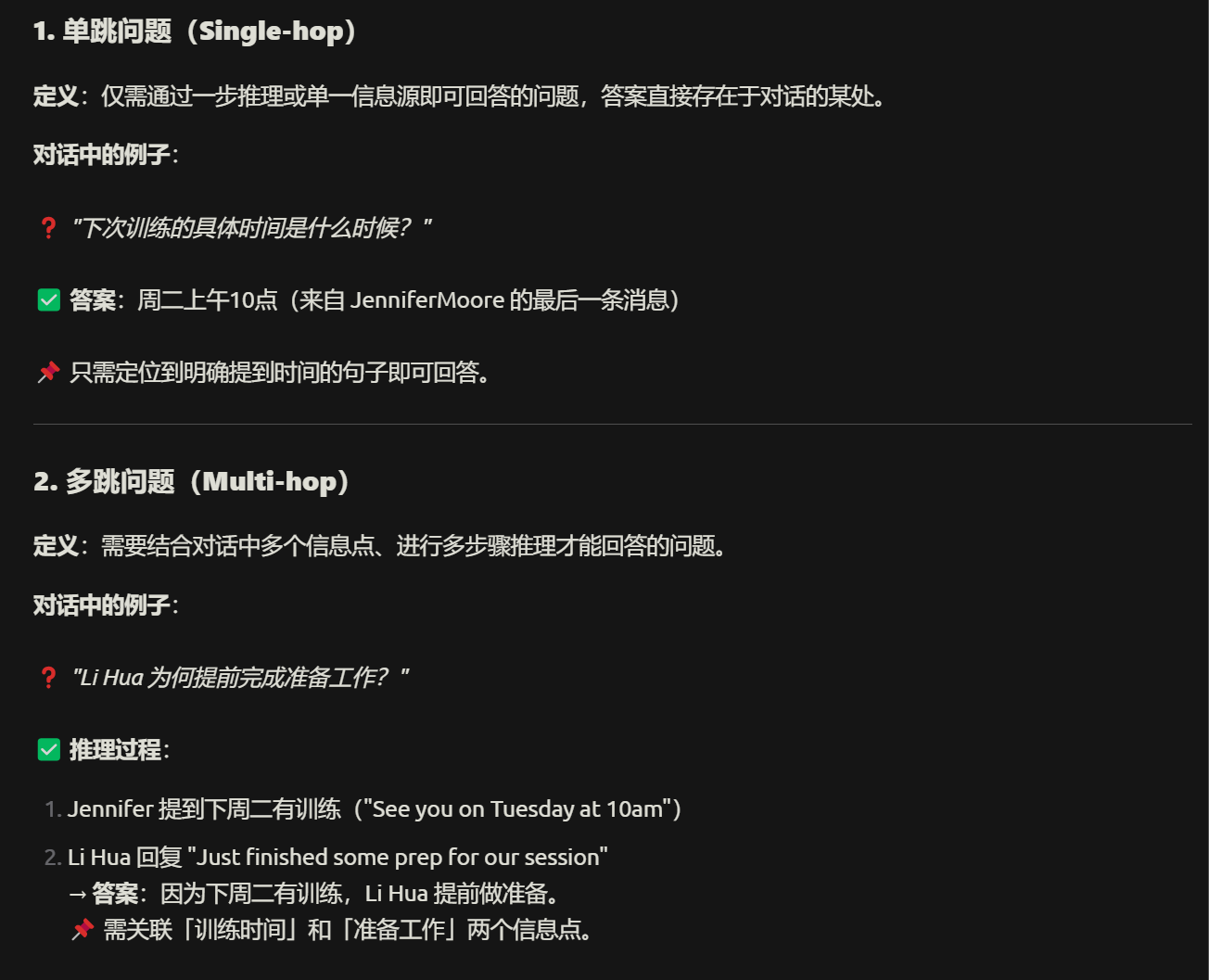

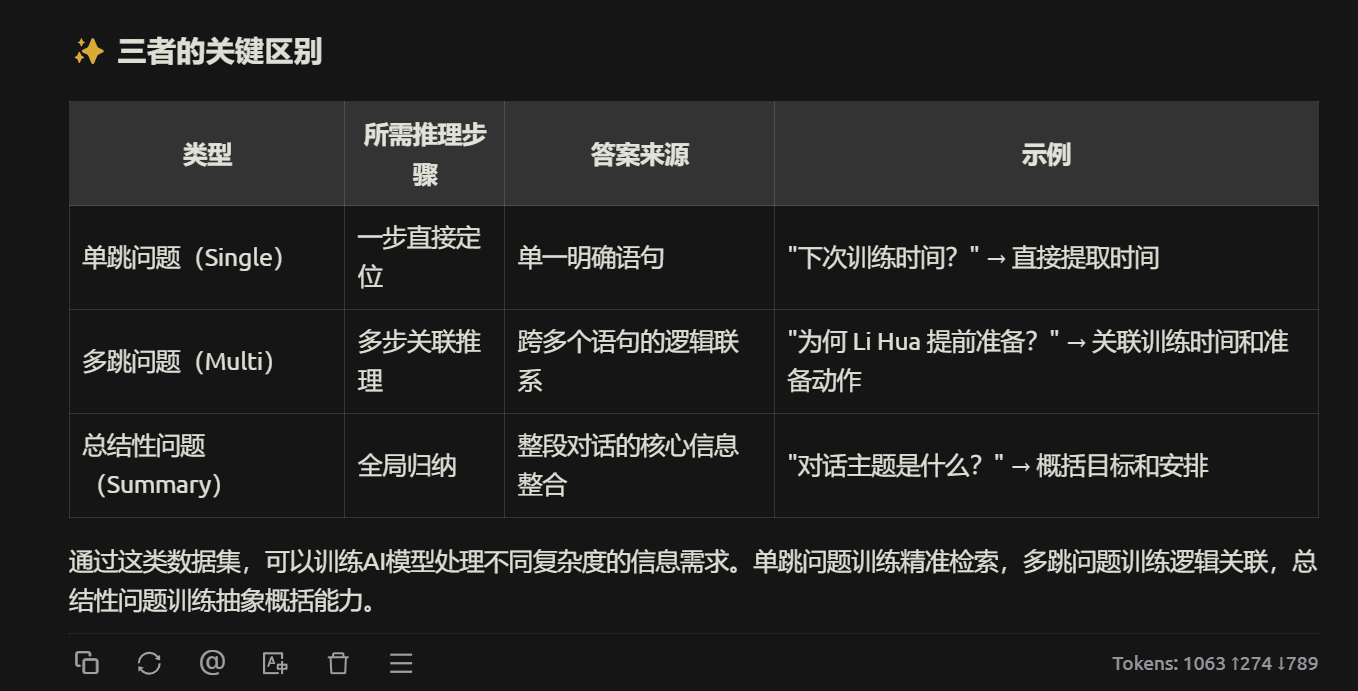
然后它的数据集里,还有一个就是问题集合,这个就麻烦了,看文档,他们竟然是动用了手工的标注
行吧
这工作量就相对来说很大了
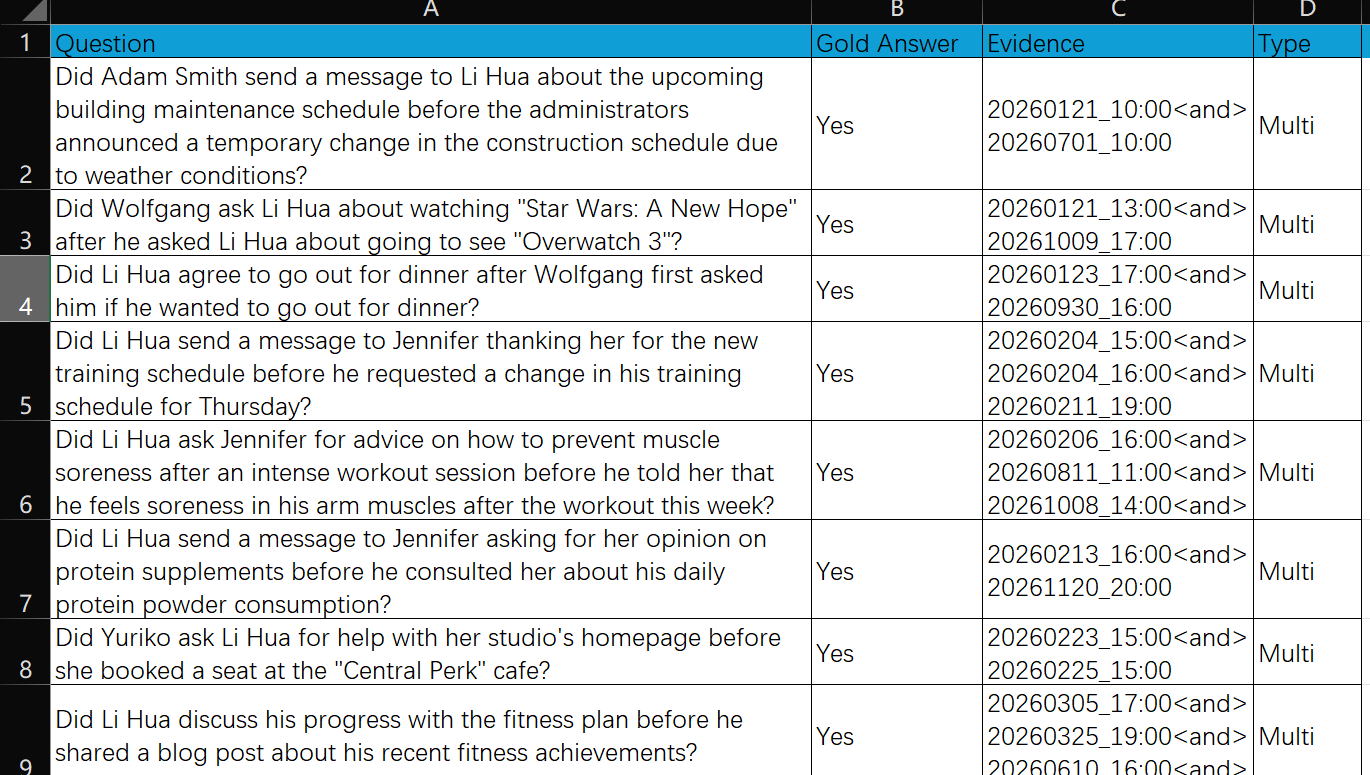
直接就标注了问题、黄金答案、以及是否是多跳
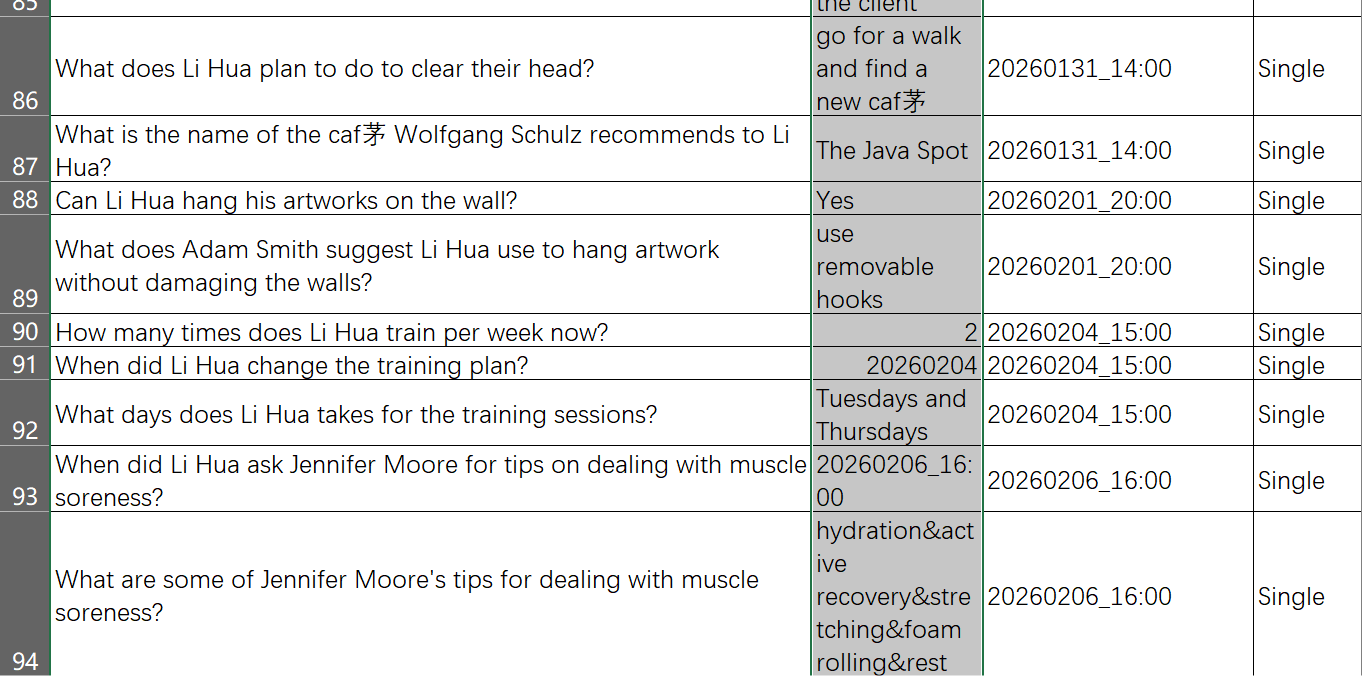

它的黄金答案里,包含:Yes/No这种判别型问答,还包含文字回复性答案,以及少量的信息不足(其实就是无法回答)
三类
所以。。。
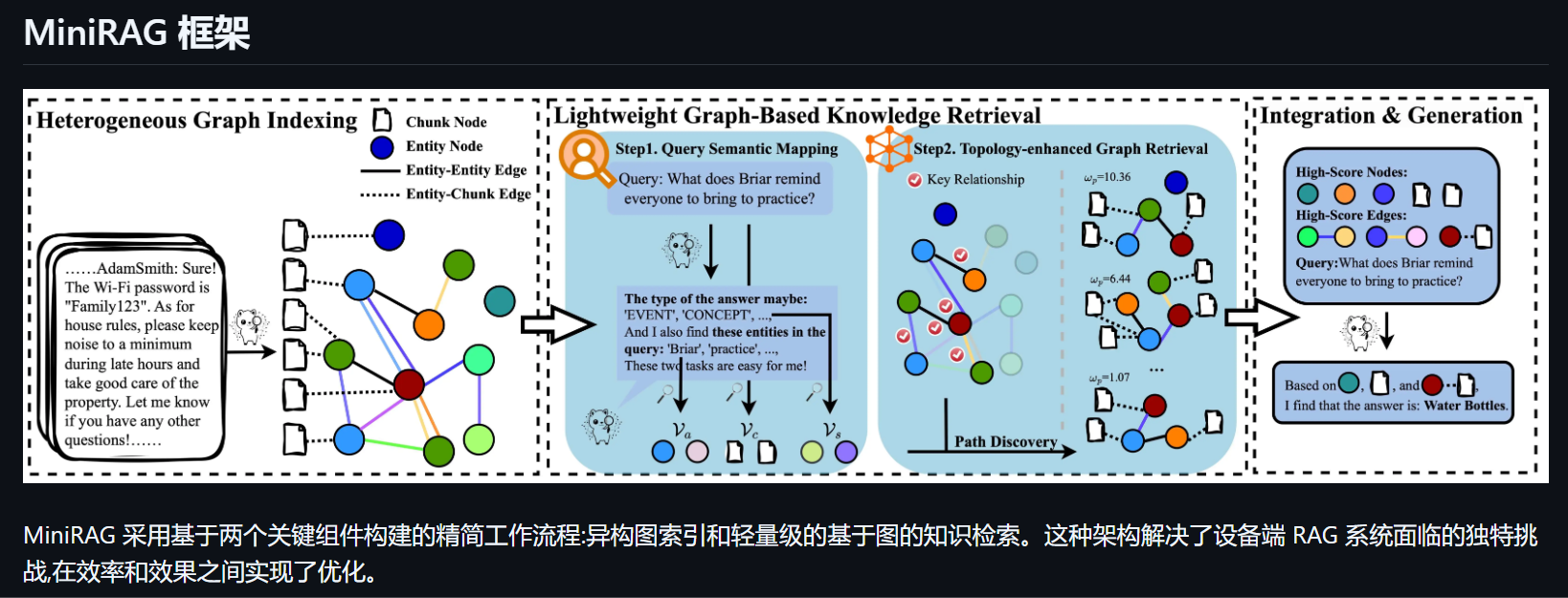
MiniRAG本身这个基于图RAG的架构,和LightRAG这类工作【有点类似于KAG的初步,整合了chunk和图】有些类似
以及它提升的性能,在10%左右来看
相比于它提升的性能而言
数据集本身倒是更有趣一些
给了我不少的启发
我倒是可以依据该数据集,来做一个类似的个人数据集,来评估提示词、pipeline以及未来可能加入的LightRAG技术
对我虚拟人格的那个项目来做数据评估
OK
以前都是工程师方法,评测也都多少有点偏主观了
大致晓得学界怎么评测一个系统的,但确实不晓得具体怎么做的
所以这个李华数据集,这种合成数据集,和标注方法,给了我一个相当不错的示范
算是给我这种工程派的小白一个很好的启发