https://huggingface.co/whyhow-ai/PatientSeek/tree/main
================
ollama run hf.co/whyhow-ai/PatientSeek一键安装
推出第一个开源 MED-LEGAL Deepseek 推理模型 PatientSeek
我们很高兴推出 PatientSeek,这是一个开源的 MED-LEGAL 推理模型,
该模型在最大的可访问医疗记录数据集之一上进行训练,可以在本地安全地运行。
我们对 DeepSeek R1 模型进行了微调,该模型基于最大的可访问病历数据集之一,
用于医疗摘要和问答。我们专门以符合 MED-LEGAL 领域需求的特定方式预处理了数以万计的病历,
并利用 DeepSeek 模型套件的推理能力来复制如何发现病历与外部事件之间的关联。
我们利用CometML进行数据集存储和实验跟踪,利用Unsloth和HuggingFace TRL进行微调,
并利用AWS Sagemaker (由NVIDIA Inception 创业计划慷慨提供的资金资助)来制作此模型,
可在此处找到https://huggingface.co/whyhow-ai/PatientSeek
要运行该模型,可以从https://huggingface.co/whyhow-ai/PatientSeek下载并按照以下
说明使用:https://unsloth.ai/blog/deepseek-r1
此模型的商业价值
在“MED-LEGAL”领域(定义为涉及法律和医疗保健考虑的行业和工作流程),我们希望优化的
两个关键方面是提高以下领域的技术水平:
疾病及诊断识别
相关性和因果关系的假设检验
我们建立此模型的价值和原因是,我们意识到“医疗法律”工作流程通常必须建立许多关联和联系,
特别是围绕需要符合法律标准的医疗因果关系问题,而这些问题在传统医疗工作流程或传统法律工
作流程中并不存在。鉴于我们团队在法律和医疗保健方面的独特背景,我们一直在帮助医疗专业人
员收集和预处理这些数据,而像 DeepSeek 这样强大的开源推理模型的出现恰逢其时。
一套以智能方式编排的模型和代理现在可以与必要的人类专业知识协作完成,以支持这些从业者
执行重复性任务。例如,快速的患者病史或有关糖尿病药物使用的问题可以为实时患者对话提供
必要的背景信息,而模型中的相关推理可以突出显示那些不太明显的内容。
为什么是现在:随着 DeepSeek r1 的发布,以及商业对自动推理的广泛接受和采用,我们可以
开始使用数据来监督我们想要的方向的推理。此外,模型的一般能力不需要扩展,而是需要更加
“磨练”,以便以最能支持从业者的方式做出响应和推理。这样,我们可以确信,随着我们扩展特
定模型和代理套件,它们将最适合所需的任务。
借助此模型,我们优化了一个足够小的模型,该模型可以离线、本地、私密且安全地运行,这对于
处理敏感患者数据的组织至关重要。我们将 O1 作为准确度的比较基准,并表明尽管 DeepSeek
的成本降低了 30 倍,并且能够在私密的本地环境中运行,但我们的性能与 O1 一样好甚至更好。
数据基础设施是性能的关键
微调并不是将随机数据转储到模型中然后就完事了。DeepSeek 的存在和进步基于精心构建数据
结构以获得更佳性能的理念,这是我们创建模型来解决业务问题的态度的一部分。
很少以微调格式收集数据,需要进行预处理以适应反映业务目标的格式。此外,不同的模型架构和
模型类型(instruct、SFT 等)需要不同的格式(一个很好的参考是 Unsloths Datasets 101,
此处:https ://docs.unsloth.ai/basics/datasets-101 )。由于这是对推理模型的微调,
我们需要为每个模型提供许多示例,格式一致且答案多样。这种预处理的价值不可低估,尤其是因
为正确的数据处理可以让组织了解最新的模型架构。
我们打算构建一套模型,旨在利用最新的推理发展,并使其适应特定的任务和用例。这些模型将有
助于执行标准任务,如相关性分析、医学知识图谱创建、实体提取、推理、采取行动、对话等,为
代理架构提供动力。我们的训练集不包含 PII,并且是合规且商业化的。
模型评估
我们对可以在本地安全运行的流行通用模型和不能在本地或私下运行的 O1 进行了基准测试,但对
于那些只关心准确性(而不是成本或隐私)的人来说,它代表了最先进的技术。
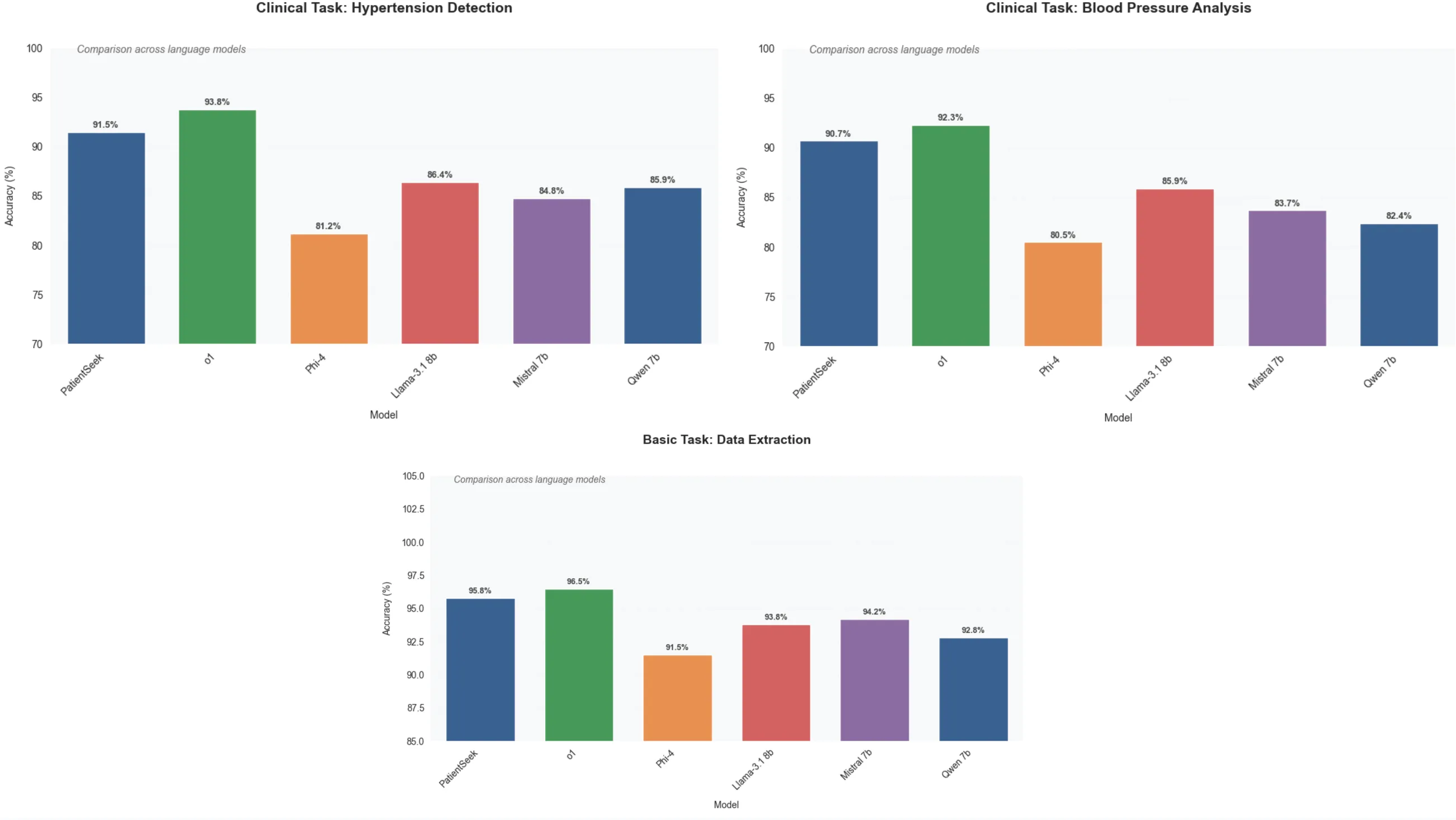
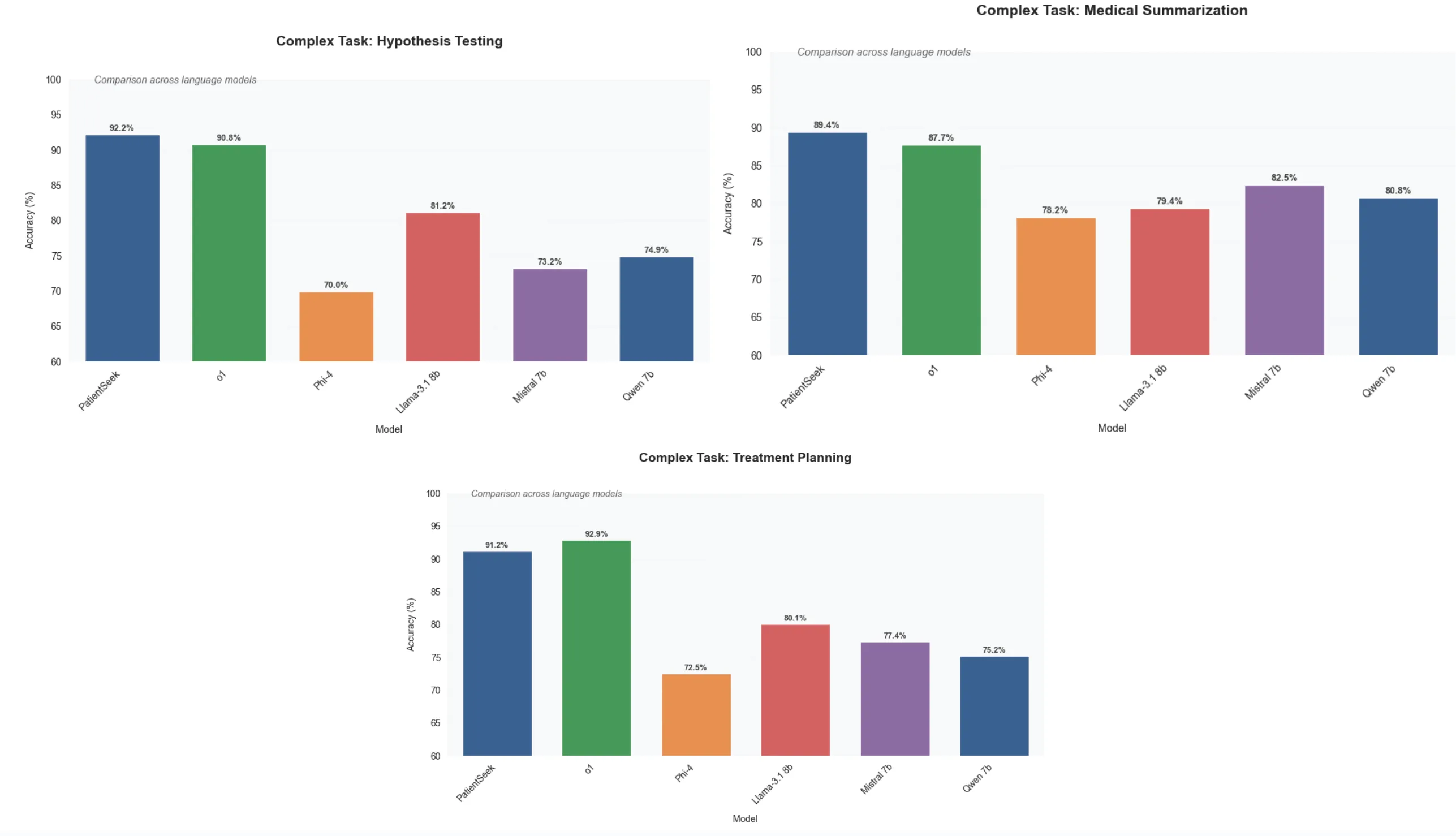
我们的评估表明 PatientSeek 在不同医疗任务中的专业能力,在复杂的医疗推理方面表现出色。
虽然所有模型在提取患者人口统计数据等基本任务上都表现良好(准确率从 89.7% 到 97.8% 不等),
但随着任务复杂性的增加,PatientSeek 显示出越来越大的优势。
在病情检测和生命体征分析等基本临床任务中,PatientSeek 的准确率达到约 90%,优于其他开源
模型,同时保持了 O1 级性能。在生成患者摘要和治疗计划等复杂医疗任务中,这一优势更加明显,
PatientSeek 的准确率保持了约 90%,而其他模型的性能则大幅下降。在复杂任务中,PatientSeek
优于 O1 和高性能开源模型,凸显了 PatientSeek 的专业医疗能力,这是通过专注于医疗文档和临
床工作流程的培训以及专门微调的医疗 QA 实现的。
复杂推理任务
基本任务
这些结果表明,虽然通用语言模型可以充分处理基本的医疗任务,但 PatientSeek 等专用模型可以
为更复杂的推理过程和医疗应用带来巨大好处。这对于寻求可靠自动化复杂医疗文档和分析任务的提供商尤其重要。
即使对于更基本的任务,PatientSeek 也明显优于其他本地运行的模型,并且与 O1 具有竞争力,
尤其是当我们考虑到成本和本地运行能力时。相比之下,DeepSeek R1 作为 API 比 O1 少约 27 倍。
在我们的案例中,对于 PatientSeek,它的成本明显更低。我们在 AWS 上托管了 DeepSeek 模型,
每个基本问题(30k 输入,2k 输出)的成本不到 0.01 美元,每个更复杂的问题的成本仍然不到 0.05 美元,
即使有 r1 的详细推理输出。我们还通过 Ollama 在 M2 Mac 上运行该系统,它在功能上是免费的。
PatientSeek 是第一个开源、本地运行、根据患者记录进行微调的 R1 推理模型,该模型公开可用,
在法律医学领域具有人类水平的理解能力。随着我们继续开发模型和构建支持 MED-LEGAL 工作流程的产品,
为了快速了解患者的病史或建立患者特定因果之间的相关关联,我们将更新和调整最新模型,
以解决这些从业者面临的最相关问题。
如果您有同样的情况,请在此处联系我们或在WhyHow.AI关注我们的工作。======================================
可惜这个工作没有公开训练数据集
以及测试的数据集
只能说可以玩玩看吧
ollama run hf-mirror.com/whyhow-ai/PatientSeek====================================
它的任务主要就是假设检验、高血压的检测、数据提取、诊疗计划
问题这些。。。有太专业了
# 基础设置
FROM ./PatientSeek-Q4_K_M.ggufollama create patientseek -f .\Modelfile
额,果然微调后的模型都很神经病啊。。。。