uv python install cpython-3.12.8-windows-x86_64-none先用uv安装小于3.13版本的python
uv init crewai_demo3 --python 3.12.8
uv venv
.venv\Scripts\activatellm = LLM(model="volcengine/ep-20250204220334-l2q5g",
api_key="xxxxxxxxxxxxxx")然后火山引擎是这么搞
uv add crewai接着添加依赖本身
因为我是需要跑代码
https://docs.crewai.com/tools/codeinterpretertool
uv add crewai[tools]所以我又添加了tools的依赖
from crewai import LLM, Agent, Task, Crew, Process
from crewai_tools import CodeInterpreterTool
llm = LLM(model="volcengine/ep-20250204220334-l2q5g",
api_key="xxxxx")
# Initialize the tool
code_interpreter = CodeInterpreterTool()
# Define an agent that uses the tool
programmer_agent = Agent(
role="Python Programmer",
goal="Write and execute Python code to solve problems",
backstory="An expert Python programmer who can write efficient code to solve complex problems.",
tools=[code_interpreter],
verbose=True,
llm=llm
)
# Example task to generate and execute code
coding_task = Task(
description="Write a Python function to calculate the Fibonacci sequence up to the 10th number and print the result.",
expected_output="The Fibonacci sequence up to the 10th number.",
agent=programmer_agent,
)
# Create and run the crew
crew = Crew(
agents=[programmer_agent],
tasks=[coding_task],
verbose=True,
process=Process.sequential,
)
result = crew.kickoff() File "E:\development\crewai_demo3\.venv\Lib\site-packages\requests\sessions.py", line 637, in post
return self.request("POST", url, data=data, json=json, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\development\crewai_demo3\.venv\Lib\site-packages\requests\sessions.py", line 589, in request
resp = self.send(prep, **send_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
return self._session.post(
^^^^^^^^^^^^^^^^^^^
File "E:\development\crewai_demo3\.venv\Lib\site-packages\requests\sessions.py", line 637, in post
return self.request("POST", url, data=data, json=json, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\development\crewai_demo3\.venv\Lib\site-packages\requests\sessions.py", line 589, in request
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\development\crewai_demo3\.venv\Lib\site-packages\requests\sessions.py", line 589, in request
File "E:\development\crewai_demo3\.venv\Lib\site-packages\requests\sessions.py", line 589, in request
resp = self.send(prep, **send_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\development\crewai_demo3\.venv\Lib\site-packages\requests\sessions.py", line 703, in send
r = adapter.send(request, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\development\crewai_demo3\.venv\Lib\site-packages\requests\adapters.py", line 698, in send
raise SSLError(e, request=request)
requests.exceptions.SSLError: HTTPSConnectionPool(host='telemetry.crewai.com', port=4319):
Max retries exceeded with url: /v1/traces (Caused by SSLError(SSLCertVerificationError(1,
'[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: certificate has expired (_ssl.c:1000)')))
PS E:\development\crewai_demo3>我特么的,报错啊。。。关键是,我没有要求你trace啊,太恶心了
说是访问telemetry.crewai.com遥测站点报错了。。。
无语
https://docs.crewai.com/telemetry

import os
# 设置环境变量(必须在导入OpenTelemetry库之前)
os.environ['OTEL_SDK_DISABLED'] = 'true' # 注意值是字符串'true'用这段代码把它关掉
# Initialize the tool
code_interpreter = CodeInterpreterTool(unsafe_mode=True)还有就是记得让它可以在host上运行
from crewai import LLM, Agent, Task, Crew, Process
from crewai_tools import CodeInterpreterTool
import os
# 设置环境变量(必须在导入OpenTelemetry库之前)
os.environ['OTEL_SDK_DISABLED'] = 'true' # 注意值是字符串'true'
llm = LLM(model="volcengine/ep-20250204220334-l2q5g",
api_key="xxxxxxxx")
# Initialize the tool
code_interpreter = CodeInterpreterTool(unsafe_mode=True)
# Define an agent that uses the tool
programmer_agent = Agent(
role="Python Programmer",
goal="Write and execute Python code to solve problems",
backstory="An expert Python programmer who can write efficient code to solve complex problems.",
tools=[code_interpreter],
verbose=True,
llm=llm
)
# Example task to generate and execute code
coding_task = Task(
description="Write a Python function to calculate the Fibonacci sequence up to the 10th number and print the result.",
expected_output="The Fibonacci sequence up to the 10th number.",
agent=programmer_agent,
)
# Create and run the crew
crew = Crew(
agents=[programmer_agent],
tasks=[coding_task],
verbose=True,
process=Process.sequential,
)
result = crew.kickoff()于是可以跑的通的代码如上所示
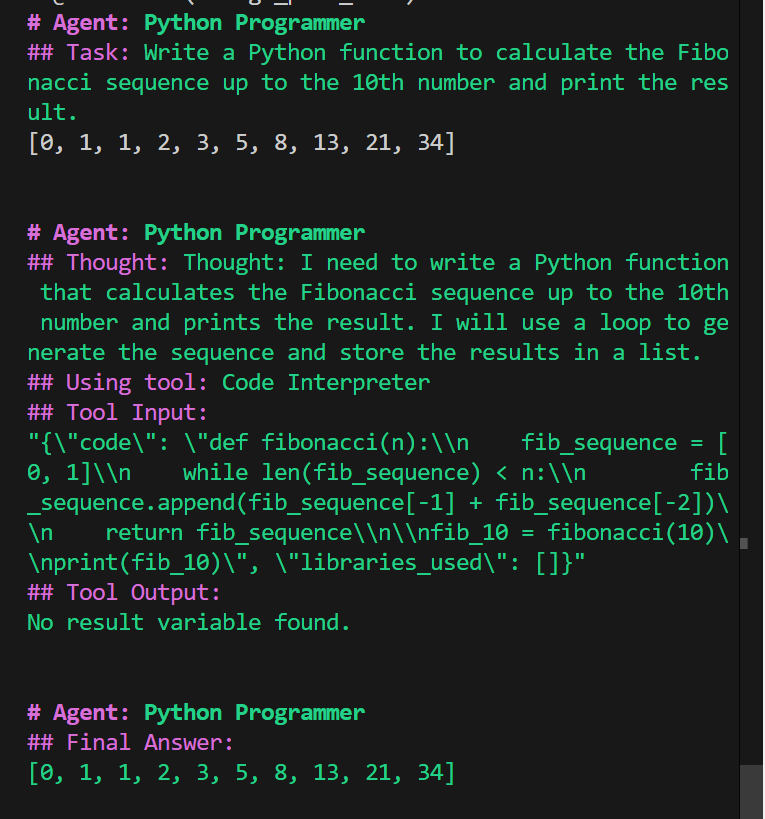
虽然确实输出结果了。。。但我有点害怕啊,这玩意真的是Tool Output么?
然后更有趣的是,crewai干脆做了一个插件市场
https://docs.crewai.com/tools/composiotool
有269个工具可以直接调用
-----------------------
接着实验一下RAGTool,虽然它的RAGTool更像是一个开箱即用的东西,但确实看上去API非常简洁
https://docs.crewai.com/tools/ragtool#agent-integration-example
https://docs.crewai.com/concepts/knowledge
我们先从最简单的开始玩起吧
from crewai import Agent, Task, Crew, Process, LLM
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
import os
# 设置环境变量(必须在导入OpenTelemetry库之前)
os.environ['OTEL_SDK_DISABLED'] = 'true' # 注意值是字符串'true'
#从环境变量取一下火山引擎的KEY出来
huoshan_key = os.getenv("HUOSHAN_API_KEY")
#litellm初始化火山引擎的方法
llm = LLM(model="volcengine/ep-20250204220334-l2q5g",
api_key=huoshan_key,temperature=0)
# Create a knowledge source
content = "Users name is John. He is 30 years old and lives in San Francisco."
string_source = StringKnowledgeSource(
content=content,
)
# Create an agent with the knowledge store
agent = Agent(
role="About User",
goal="You know everything about the user.",
backstory="""You are a master at understanding people and their preferences.""",
verbose=True,
allow_delegation=False,
llm=llm,
embedder={
"provider": "ollama",
"config": {
"model": "bge-m3:latest",
"api_key": "xxxx",
}
},
)
task = Task(
description="Answer the following questions about the user: {question}",
expected_output="An answer to the question.",
agent=agent,
)
crew = Crew(
agents=[agent],
tasks=[task],
verbose=True,
process=Process.sequential,
knowledge_sources=[string_source], # Enable knowledge by adding the sources here. You can also add more sources to the sources list.
)
result = crew.kickoff(inputs={"question": "What city does John live in and how old is he?"})报错:Failed to upsert documents: APIStatusError.__init__() missing 2 required keyword-only arguments: 'response' and 'body'
然后看了一下是嵌入的问题:
https://github.com/crewAIInc/crewAI/issues/2150
from crewai import Agent, Task, Crew, Process, LLM
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
import os
# 设置环境变量(必须在导入OpenTelemetry库之前)
os.environ['OTEL_SDK_DISABLED'] = 'true' # 注意值是字符串'true'
#从环境变量取一下火山引擎的KEY出来
huoshan_key = os.getenv("HUOSHAN_API_KEY")
#litellm初始化火山引擎的方法
llm = LLM(model="volcengine/ep-20250204220334-l2q5g",
api_key=huoshan_key,temperature=0)
# Create a knowledge source
content = "Users name is John. He is 30 years old and lives in San Francisco."
string_source = StringKnowledgeSource(
content=content,
)
# Create an agent with the knowledge store
agent = Agent(
role="About User",
goal="You know everything about the user.",
backstory="""You are a master at understanding people and their preferences.""",
verbose=True,
allow_delegation=False,
llm=llm,
)
task = Task(
description="Answer the following questions about the user: {question}",
expected_output="An answer to the question.",
agent=agent,
)
crew = Crew(
agents=[agent],
tasks=[task],
verbose=True,
process=Process.sequential,
embedder={
"provider": "ollama",
"config": {
"model": "bge-m3:latest",
"api_key": "xxxx",
}
},
knowledge_sources=[string_source], # Enable knowledge by adding the sources here. You can also add more sources to the sources list.
)
result = crew.kickoff(inputs={"question": "What city does John live in and how old is he?"})修改代码成这样了,跑通了
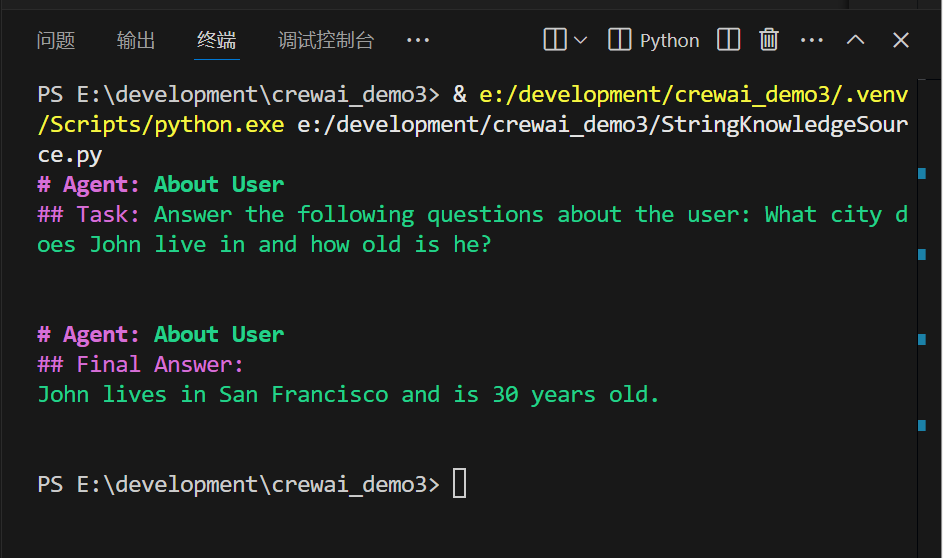
要点其实也很简单,需要在crew的初始化那里,把kb的嵌入器配置好就行了
然后开始跑RAG_TOOLS这个,我才知道,它是集成了另外一个库
https://docs.embedchain.ai/get-started/quickstart
叫embedchain.ai,行吧,也算是工业外包了
from crewai import LLM, Agent
from crewai.project import agent
from crewai_tools import RagTool
import os
# 设置环境变量(必须在导入OpenTelemetry库之前)
os.environ['OTEL_SDK_DISABLED'] = 'true' # 注意值是字符串'true'
#从环境变量取一下火山引擎的KEY出来
huoshan_key = os.getenv("HUOSHAN_API_KEY")
#litellm初始化火山引擎的方法
llm = LLM(model="volcengine/ep-20250204220334-l2q5g",
api_key=huoshan_key,temperature=0)
# Create a RAG tool with custom configuration
config = {
"embedder": {
"provider": "ollama",
"config": {
"model": "bge-m3:latest",
}
}
}
# Initialize the tool and add content
rag_tool = RagTool(llm=llm,config=config)
rag_tool.add(data_type="web_page", source="https://docs.crewai.com")
# Define an agent with the RagTool
@agent
def knowledge_expert(self) -> Agent:
return Agent(
config=self.agents_config["knowledge_expert"],
allow_delegation=False,
tools=[rag_tool],
)
然后代码是有问题的,官方,估计是因为embedchain那边修改了
rag_tool.add(data_type="web_page", source="https://docs.crewai.com")比如这么些
from crewai import LLM, Agent, Crew, Process, Task
from crewai.project import agent
from crewai_tools import RagTool
import os
# 设置环境变量(必须在导入OpenTelemetry库之前)
os.environ['OTEL_SDK_DISABLED'] = 'true' # 注意值是字符串'true'
#从环境变量取一下火山引擎的KEY出来
huoshan_key = os.getenv("HUOSHAN_API_KEY")
#litellm初始化火山引擎的方法
llm = LLM(model="volcengine/ep-20250204220334-l2q5g",
api_key=huoshan_key,temperature=0)
# Create a RAG tool with custom configuration
config = {
"embedder": {
"provider": "ollama",
"config": {
"model": "bge-m3:latest",
}
}
}
# Initialize the tool and add content
rag_tool = RagTool(llm=llm,config=config)
rag_tool.add(data_type="web_page", source="https://docs.crewai.com")
# 定义 Project 类(关键修复点)
class MyProject():
def __init__(self):
super().__init__()
# 定义 agents 配置(必须)
self.agents_config = {
"knowledge_expert": {
"role": "知识专家",
"goal": "准确回答关于 CrewAI 的问题",
"backstory": "你是一个擅长使用 RAG 工具的技术文档专家",
"verbose": True
}
}
@agent # 装饰器现在在 Project 类中
def knowledge_expert(self) -> Agent:
return Agent(
config=self.agents_config["knowledge_expert"],
allow_delegation=False,
tools=[rag_tool], # 使用全局 rag_tool
llm=llm # 显式传递 LLM
)
# 初始化项目
project = MyProject()
knowledge_agent = project.knowledge_expert() # 正确获取 Agent 实例
task = Task(
description="Answer the following questions about the crewai: {question}",
expected_output="An answer to the question.",
agent=knowledge_agent,
)
crew = Crew(
agents=[knowledge_agent],
tasks=[task],
verbose=True,
process=Process.sequential,
)
result = crew.kickoff(inputs={"question": "用中文回答,crewai支持解析docx么?"})笑死,跑是跑通了,但和没跑通也没多大区别
底层用的chroma,切分策略大到跟没有一样
哈哈哈哈
所以。。。你看吧
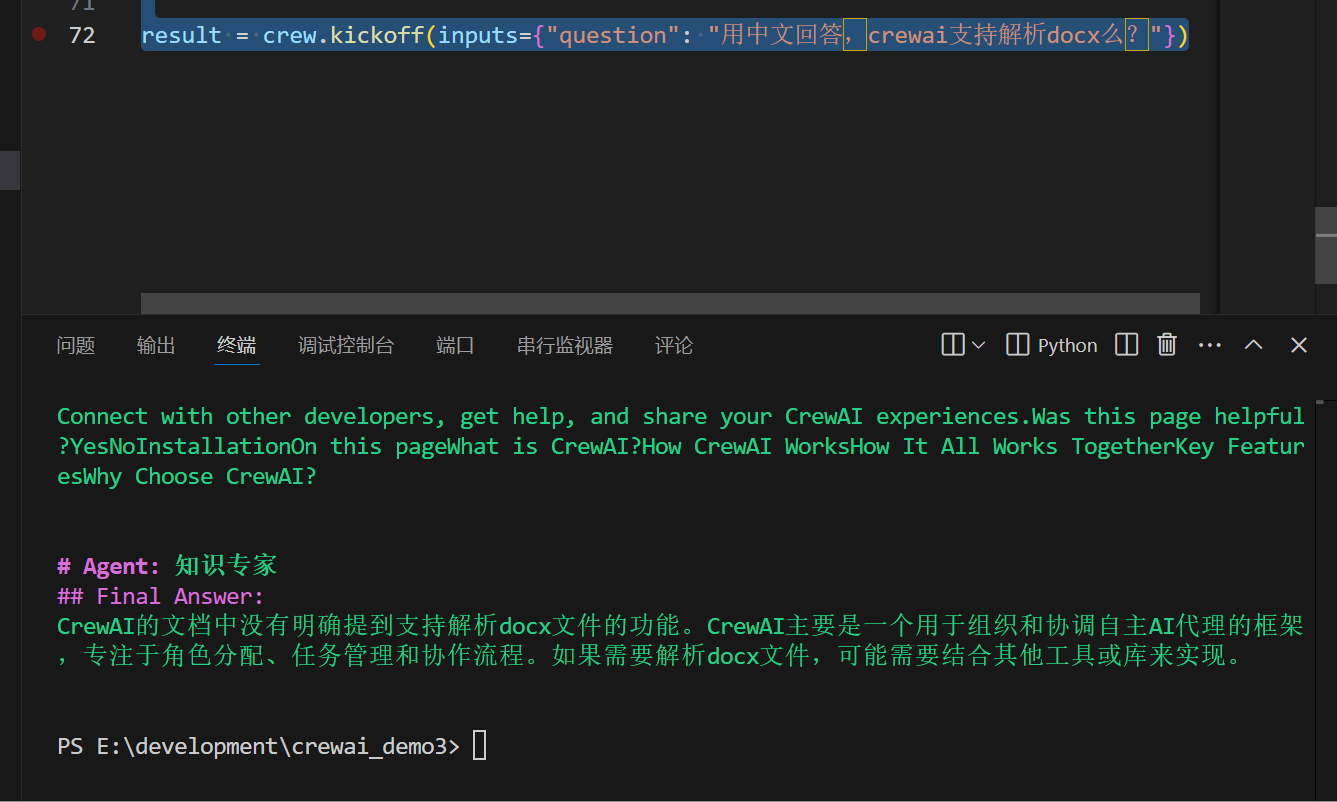
开箱即用的RAG,就不要期待太高。。。。没办法