https://help.aliyun.com/zh/model-studio/user-guide/qwen-omni
官方文档

PS E:\development> mkdir omni_demo1
目录: E:\development
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/3/27 14:02 omni_demo1
PS E:\development> cd .\omni_demo1\
PS E:\development\omni_demo1> uv init
Initialized project `omni-demo1`
PS E:\development\omni_demo1> uv venv
Using CPython 3.12.8
Creating virtual environment at: .venv
Activate with: .venv\Scripts\activate
PS E:\development\omni_demo1> .venv\Scripts\activate
(omni_demo1) PS E:\development\omni_demo1>建立并激活环境
uv add openai安装好依赖
【文本输入】
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-omni-turbo",
messages=[{"role": "user", "content": "你是谁"}],
# 设置输出数据的模态,当前支持两种:["text","audio"]、["text"]
modalities=["text", "audio"],
audio={"voice": "Cherry", "format": "wav"},
# stream 必须设置为 True,否则会报错
stream=True,
stream_options={"include_usage": True},
)
for chunk in completion:
if chunk.choices:
print(chunk.choices[0].delta)
else:
print(chunk.usage)没有问题
可以输出
但是比较尴尬啊,这。。出来还需要能播放啊

OK,有了
uv add pyaudio numpy soundfile先安装依赖
import os
from openai import OpenAI
import base64
import numpy as np
import soundfile as sf
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-omni-turbo",
messages=[{"role": "user", "content": "你是谁"}],
# 设置输出数据的模态,当前支持两种:["text","audio"]、["text"]
modalities=["text", "audio"],
audio={"voice": "Cherry", "format": "wav"},
# stream 必须设置为 True,否则会报错
stream=True,
stream_options={"include_usage": True},
)
audio_string = ""
for chunk in completion:
if chunk.choices:
if hasattr(chunk.choices[0].delta, "audio"):
try:
audio_string += chunk.choices[0].delta.audio["data"]
except Exception as e:
print(chunk.choices[0].delta.audio["transcript"])
else:
print(chunk.usage)
wav_bytes = base64.b64decode(audio_string)
audio_np = np.frombuffer(wav_bytes, dtype=np.int16)
sf.write("audio_assistant_py.wav", audio_np, samplerate=24000)
#使用PyAudio播放音频
import pyaudio
import wave
def play_audio(file_path):
wf = wave.open(file_path, 'rb')
p = pyaudio.PyAudio()
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
data = wf.readframes(1024)
while data:
stream.write(data)
data = wf.readframes(1024)
stream.stop_stream()
stream.close()
p.terminate()
play_audio("audio_assistant_py.wav")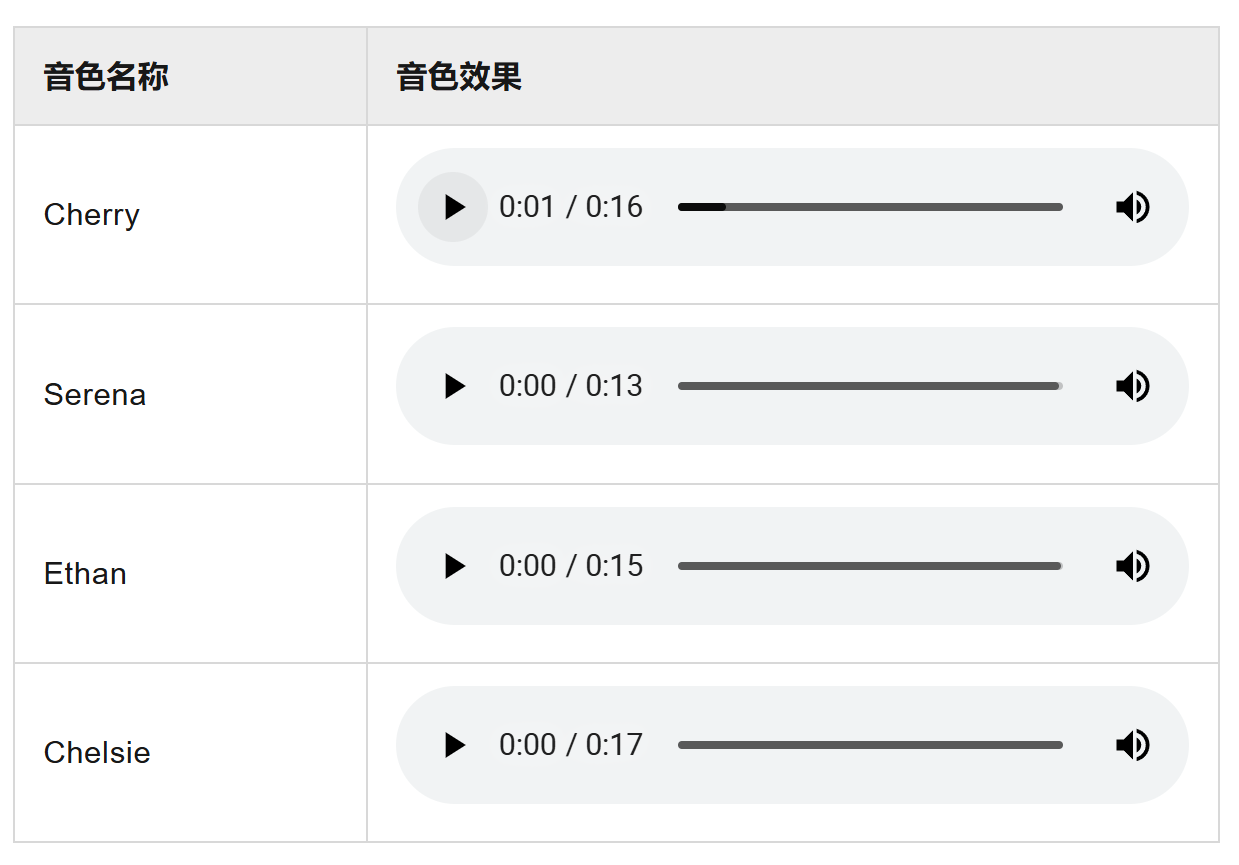
它有四种音色
还不错的
import os
from openai import OpenAI
import base64
import numpy as np
import soundfile as sf
import requests
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
def encode_audio(audio_path):
with open(audio_path, "rb") as audio_file:
return base64.b64encode(audio_file.read()).decode("utf-8")
base64_audio = encode_audio("welcome.mp3")
completion = client.chat.completions.create(
model="qwen-omni-turbo",
messages=[
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}],
},
{
"role": "user",
"content": [
{
"type": "input_audio",
"input_audio": {
"data": f"data:;base64,{base64_audio}",
"format": "mp3",
},
},
{"type": "text", "text": "这段音频在说什么"},
],
},
],
# 设置输出数据的模态,当前支持两种:["text","audio"]、["text"]
modalities=["text", "audio"],
audio={"voice": "Cherry", "format": "wav"},
# stream 必须设置为 True,否则会报错
stream=True,
stream_options={"include_usage": True},
)
for chunk in completion:
if chunk.choices:
print(chunk.choices[0].delta)
else:
print(chunk.usage)最后一段呢,则是它编码本地文件后使用音频和模型对话的例子.....
最后所有的测试代码都放上了githhub
https://github.com/lemonhall/omni_demo1
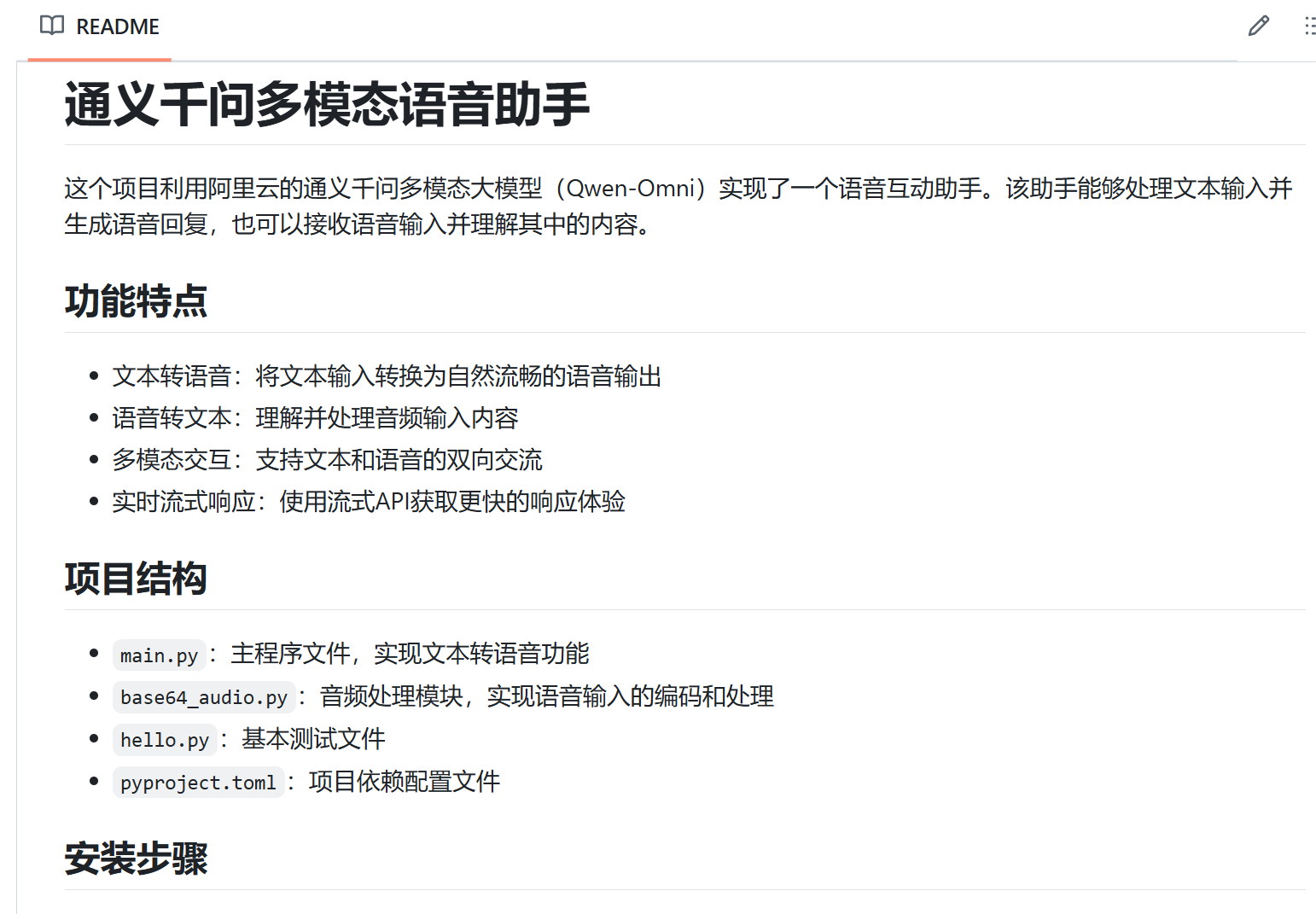
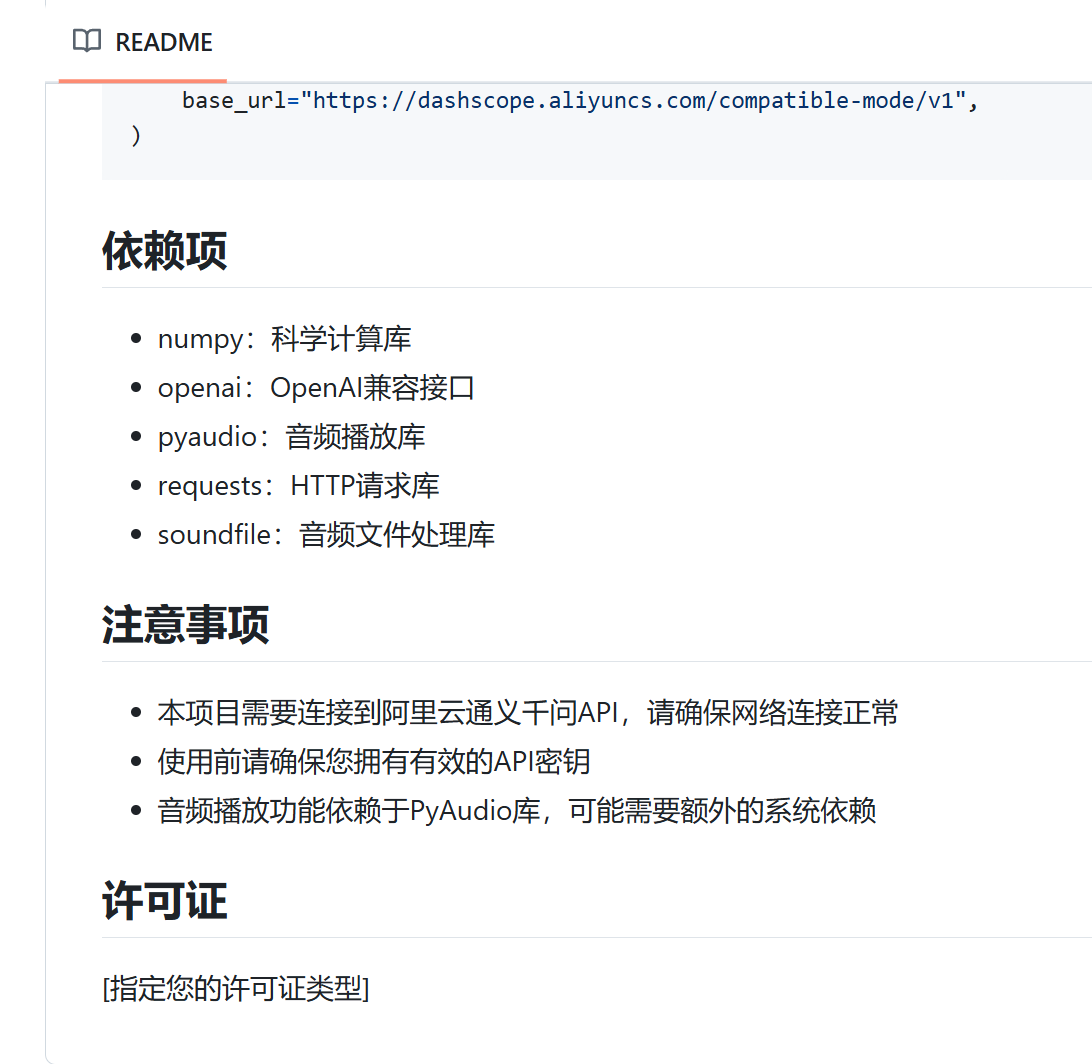
有3.7帮我写的README.md
这个时代太幸福了
接下来就是要用fastapi那些看怎么包装一下这个东西,可以方便的使用啥的。。。