https://github.com/unclecode/crawl4ai
PS E:\development> mkdir craw4ai_demo
目录: E:\development
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/4/1 9:12 craw4ai_demo
PS E:\development> cd .\craw4ai_demo\
PS E:\development\craw4ai_demo> uv init
Initialized project `craw4ai-demo`
PS E:\development\craw4ai_demo> uv venv
Using CPython 3.12.8
Creating virtual environment at: .venv
Activate with: .venv\Scripts\activate
PS E:\development\craw4ai_demo> .venv\Scripts\activate
(craw4ai_demo) PS E:\development\craw4ai_demo>安装软件本身
uv pip install -U crawl4ai
安装软件依赖的软件
(craw4ai_demo) PS E:\development\craw4ai_demo> crawl4ai-setup
[INIT].... → Running post-installation setup...
[INIT].... → Installing Playwright browsers...
Removing unused browser at C:\Users\lemon\AppData\Local\ms-playwright\chromium_headless_shell-1155
Downloading Chromium 134.0.6998.35 (playwright build v1161) from
https://cdn.playwright.dev/dbazure/download/playwright/builds/chromium/1161/chromium-win64.zip
141.8 MiB [====================] 100% 0.0s
Chromium 134.0.6998.35 (playwright build v1161) downloaded to
C:\Users\lemon\AppData\Local\ms-playwright\chromium-1161
Downloading Chromium Headless Shell 134.0.6998.35 (playwright build v1161) from
https://cdn.playwright.dev/dbazure/download/playwright/builds/chromium/1161/chromium-headless-shell-win64.zip
87.8 MiB [====================] 100% 0.0s
Chromium Headless Shell 134.0.6998.35 (playwright build v1161) downloaded to
C:\Users\lemon\AppData\Local\ms-playwright\chromium_headless_shell-1161
[COMPLETE] ● Playwright installation completed successfully.
[INIT].... → Starting database initialization...
[COMPLETE] ● Database backup created at: C:\Users\lemon\.crawl4ai\crawl4ai.db.backup_20250401_091427
[INIT].... → Starting database migration...
[COMPLETE] ● Migration completed. 0 records processed.
[COMPLETE] ● Database initialization completed successfully.
[COMPLETE] ● Post-installation setup completed!
(craw4ai_demo) PS E:\development\craw4ai_demo>其实就是chrome
验证一下安装
# Verify your installation
crawl4ai-doctor
(craw4ai_demo) PS E:\development\craw4ai_demo> crawl4ai-doctor
[INIT].... → Running Crawl4AI health check...
[INIT].... → Crawl4AI 0.5.0.post8
[TEST].... ℹ Testing crawling capabilities...
[EXPORT].. ℹ Exporting PDF and taking screenshot took 1.04s
[FETCH]... ↓ https://crawl4ai.com... | Status: True | Time: 5.38s
[SCRAPE].. ◆ https://crawl4ai.com... | Time: 0.034s
[COMPLETE] ● https://crawl4ai.com... | Status: True | Total: 5.42s
[COMPLETE] ● ✅ Crawling test passed!
(craw4ai_demo) PS E:\development\craw4ai_demo>命令行使用
# Basic crawl with markdown output
crwl https://www.nbcnews.com/business -o markdown
# Deep crawl with BFS strategy, max 10 pages
crwl https://docs.crawl4ai.com --deep-crawl bfs --max-pages 10
# Use LLM extraction with a specific question
crwl https://www.example.com/products -q "Extract all product prices"第一种单页面
crwl https://www.nbcnews.com/business -o markdown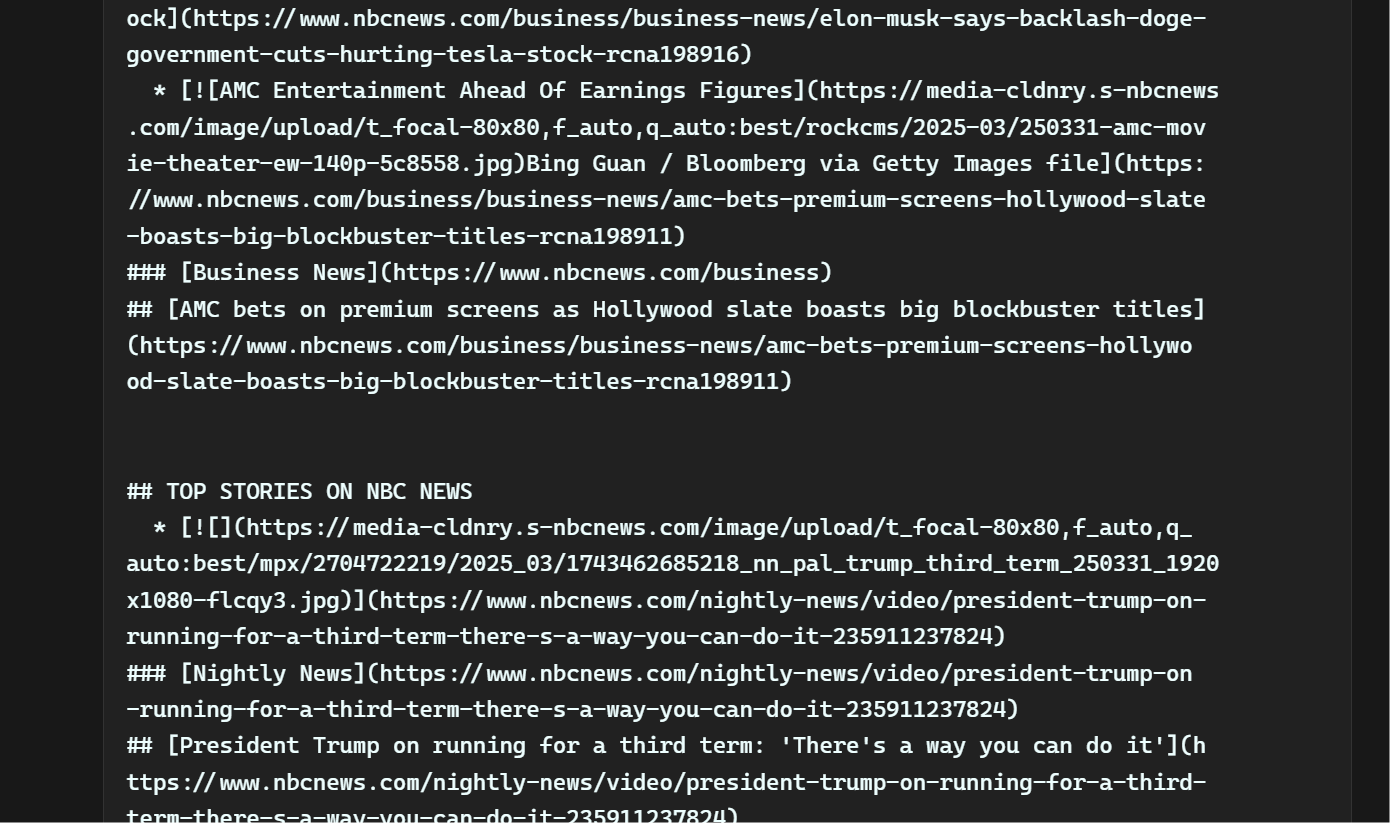
第二种,带一定deep的
# Deep crawl with BFS strategy, max 10 pages
crwl https://docs.crawl4ai.com --deep-crawl bfs --max-pages 10第三种把单个页面,直接当作RAG来查的
# Use LLM extraction with a specific question
crwl https://www.example.com/products -q "Extract all product prices"还可以当成一个任务队列去用的:
import requests
# Submit a crawl job
response = requests.post(
"http://localhost:11235/crawl",
json={"urls": "https://example.com", "priority": 10}
)
task_id = response.json()["task_id"]
# Continue polling until the task is complete (status="completed")
result = requests.get(f"http://localhost:11235/task/{task_id}")总是就是挺好的
我看了一下,github上还有很多的mcp的实现,但很奇怪为啥作者不自己写一个官方的
------------------------------------------
OK,然后我做了一个总结机器人:
第一步,把arxiv下的特定页面保存下来:
(craw4ai_demo) PS E:\development\craw4ai_demo> $env:PYTHONIOENCODING = "utf-8"
(craw4ai_demo) PS E:\development\craw4ai_demo> $env:PYTHONUTF8 = "1"
(craw4ai_demo) PS E:\development\craw4ai_demo> crwl "https://arxiv.org/list/cs.AI/recent?skip=0&show=250" -o markdown |
Out-File -Encoding utf8 arxiv-20250401.mdhttps://arxiv.org/list/cs.AI/recent?skip=0&show=250
powershell下,有个编码问题,真恶心
第二步:写总结
实验阶段,先用的V3
聚类一下所有论文的主题,并且统计一下该主题下所拥有的论文数量这里是250篇,但其实是有问题的
因为4月1日,其实只有232篇论文
Here is a clustered summary of the paper themes from the provided arXiv AI submissions,
along with the count of papers in each category:
### 1. **AI Agents & Multi-Agent Systems** (32 papers)
- Focus on autonomous agents, multi-agent collaboration, and agent-based simulations.
- Examples: Retail shopping agents, scientific discovery agents, web automation agents.
### 2. **Large Language Models (LLMs) & NLP** (31 papers)
- Includes reasoning, bias evaluation, multilingual applications, and safety.
- Examples: Logical fallacy reasoning, mental health text analysis, toxicity detection.
### 3. **Computer Vision & Multimodal AI** (28 papers)
- Covers image/video generation, segmentation, and vision-language models.
- Examples: Medical image segmentation, visual grounding, diffusion models.
### 4. **Reinforcement Learning & Robotics** (22 papers)
- Focus on RL for robotics, planning, and real-world applications.
- Examples: Robotic manipulation, autonomous driving, traffic rule compliance.
### 5. **AI for Healthcare & Biomedicine** (18 papers)
- Medical imaging, drug discovery, and clinical text analysis.
- Examples: Cancer treatment prediction, pathology image compression.
### 6. **AI Safety, Ethics & Explainability** (16 papers)
- Bias mitigation, fairness, and interpretability.
- Examples: Model auditing, privacy-preserving federated learning.
### 7. **Generative Models & Diffusion Models** (15 papers)
- Image/text generation and enhancement.
- Examples: Story visualization, 3D object generation.
### 8. **Knowledge Graphs & Semantic Reasoning** (12 papers)
- Focus on structured knowledge representation and reasoning.
- Examples: Knowledge graph completion, ontology alignment.
### 9. **AI for Software Engineering** (10 papers)
- Code generation, testing, and debugging.
- Examples: LLM-based code evaluation, bug detection.
### 10. **AI for Social Good & Civic Tech** (8 papers)
- Applications in governance, education, and accessibility.
- Examples: Municipal budget chatbots, assistive tech for visually impaired users.
### 11. **Theoretical AI & Machine Learning** (7 papers)
- Foundational research in optimization, generalization, and learning dynamics.
- Examples: Deep learning optimization, continual learning.
### 12. **AI for Finance & Economics** (6 papers)
- Market prediction, risk assessment.
- Examples: Stock price forecasting, Ethereum price prediction.
### 13. **AI for Climate & Sustainability** (5 papers)
- Environmental monitoring and resource management.
- Examples: Groundwater storage estimation.
### 14. **Miscellaneous** (10 papers)
- Cross-disciplinary or niche applications (e.g., music generation, cybersecurity).
### Summary Statistics:
- **Total Papers Analyzed**: 232 (from the first 250 entries).
- **Top 3 Themes**: AI Agents (32), LLMs/NLP (31), Computer Vision (28).
This clustering reflects the diversity of AI research, with strong emphasis on autonomous systems,
language models, and multimodal applications. Let me know if you'd like deeper analysis on any category!输出其实也都是英文的
我让V3下次输出中文
以下是arXiv上提供的AI投稿论文主题分类汇总,以及每个类别的论文数量:
### 1. **AI智能体与多智能体系统**(32篇)
- 聚焦自主智能体、多智能体协作和基于智能体的模拟
- 示例:零售购物智能体、科学发现智能体、网络自动化智能体
### 2. **大语言模型(LLM)与自然语言处理**(31篇)
- 涵盖推理、偏见评估、多语言应用和安全性
- 示例:逻辑谬误推理、心理健康文本分析、毒性检测
### 3. **计算机视觉与多模态AI**(28篇)
- 包括图像/视频生成、分割和视觉-语言模型
- 示例:医学图像分割、视觉定位、扩散模型
### 4. **强化学习与机器人技术**(22篇)
- 专注于机器人强化学习、规划和现实应用
- 示例:机器人操控、自动驾驶、交通规则遵从
### 5. **医疗与生物医学AI**(18篇)
- 医学影像、药物发现和临床文本分析
- 示例:癌症治疗预测、病理图像压缩
### 6. **AI安全性、伦理与可解释性**(16篇)
- 偏见缓解、公平性和可解释性
- 示例:模型审计、隐私保护的联邦学习
### 7. **生成模型与扩散模型**(15篇)
- 图像/文本生成与增强
- 示例:故事可视化、3D物体生成
### 8. **知识图谱与语义推理**(12篇)
- 结构化知识表示与推理
- 示例:知识图谱补全、本体对齐
### 9. **软件工程AI**(10篇)
- 代码生成、测试和调试
- 示例:基于LLM的代码评估、缺陷检测
### 10. **社会公益与公民科技AI**(8篇)
- 应用于治理、教育和无障碍技术
- 示例:市政预算聊天机器人、视障用户辅助技术
### 11. **AI理论与机器学习基础**(7篇)
- 优化、泛化和学习动态的基础研究
- 示例:深度学习优化、持续学习
### 12. **金融与经济AI**(6篇)
- 市场预测、风险评估
- 示例:股价预测、以太坊价格预测
### 13. **气候与可持续性AI**(5篇)
- 环境监测与资源管理
- 示例:地下水储量估算
### 14. **其他领域**(10篇)
- 跨学科或小众应用(如音乐生成、网络安全)
### 统计摘要:
- **分析论文总数**:232篇(基于前250条记录)
- **前三大主题**:AI智能体(32)、大语言模型/NLP(31)、计算机视觉(28)
该分类体现了AI研究的多样性,重点集中在自主系统、语言模型和多模态应用。如需深入分析某个类别,请随时告知!【明后天搞一个自动总结arXiv的机器人吧,然后随机让它给我推荐几篇,我再利用记忆体把觉得有趣的文章都塞进去,最后调教好一个agent后,以后它定时给我推论文….】