参考的文档地址是:
https://mp.weixin.qq.com/s/Qx1Zy9MurIyWouifN0hQpw 下载地址:
https://ollama.com/download 我是在WSL2里面安装试试先
curl -fsSL https://ollama.com/install.sh | sh所以是以上的命令行
执行结果如下:
随便运行一个模型试试:
https://ollama.com/library/llama2-uncensored
我没管内存限制,直接运行了一下命令:
ollama run llama2-uncensored
网速还不错
3分钟左右可以搞定
已经可以聊天了,我还以为必须通过那个API啥的呢
可以和这个解码版本的聊天了
它还是有点蠢的
换阿里的
https://ollama.com/library/qwen
ollama run qwen:14b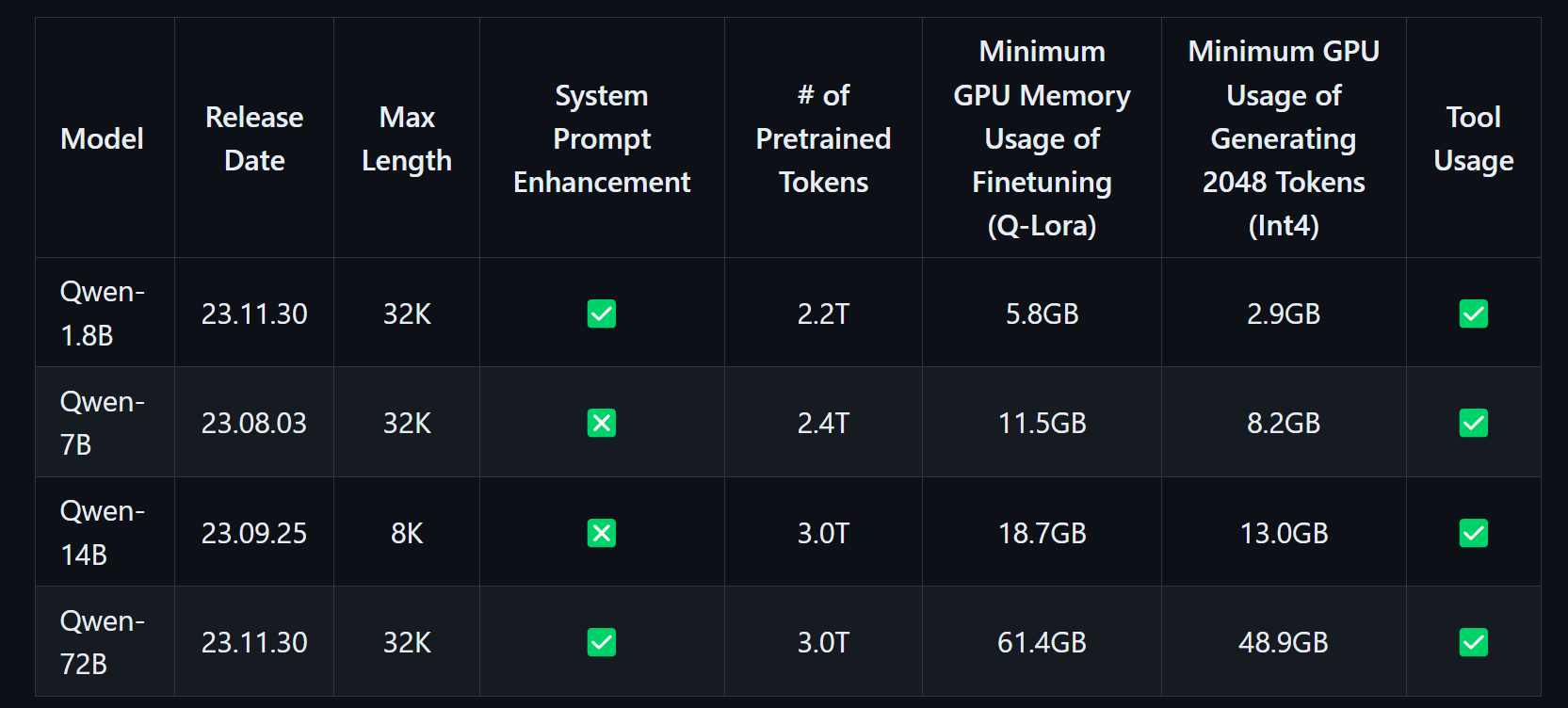
去github上看了一下
我草,我这个卡也只能跑得动8.2GB的按个7b模型啊
好吧
ollama run qwen:7b所以我应该是跑这个的

你看,也不是跑不动不是
还挺好的
14b在我的这台32G内存,8G的显卡的电脑上会直接乱码输出
换成7b的试一试
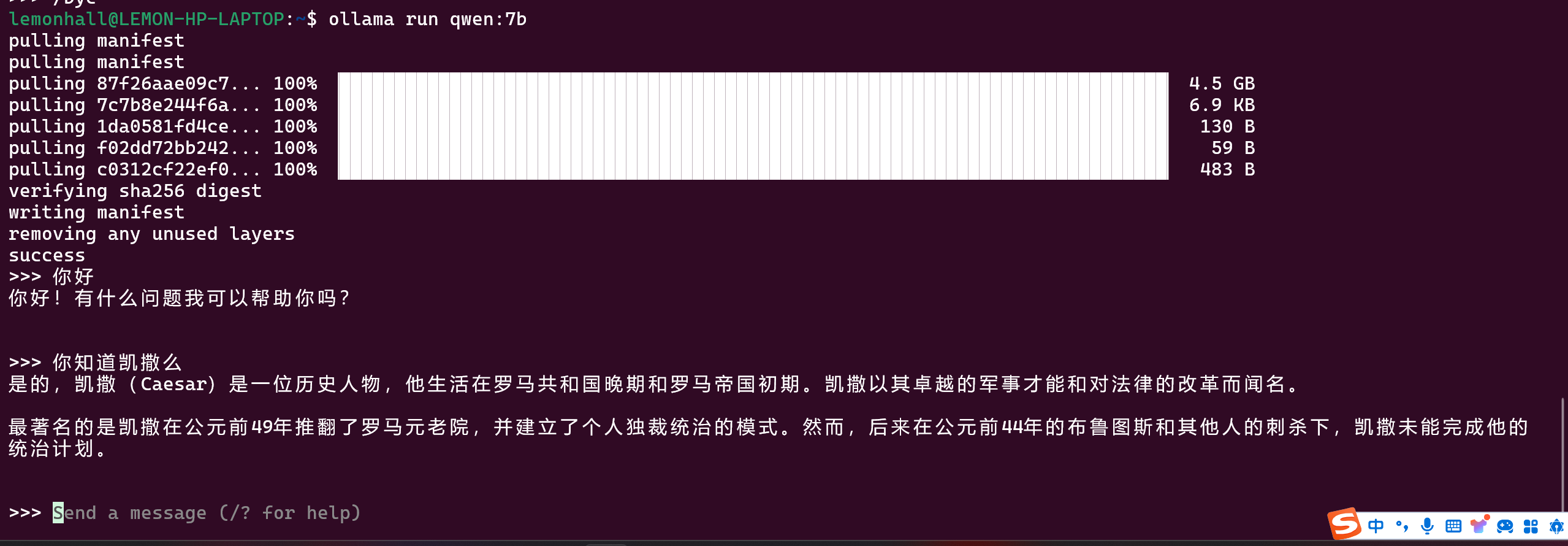
7b
就很ok
然后再来一个提示词试试角色扮演
你是盖乌斯·尤利乌斯·恺撒,你将循循善诱得回答对话者的所有问题。
然后问了那个关键问题:
您认为您生平当中最重要的战役是哪一个?大概就知道了,这个模型里的语料
对历史的有所涉及,但不多
先这样吧,没啥,还可以攒很多问题集试试