目的是把自己的一段语音train到模型里面去,试试它能不能单独分离出来我个人的声音,从带中文的BGM里面
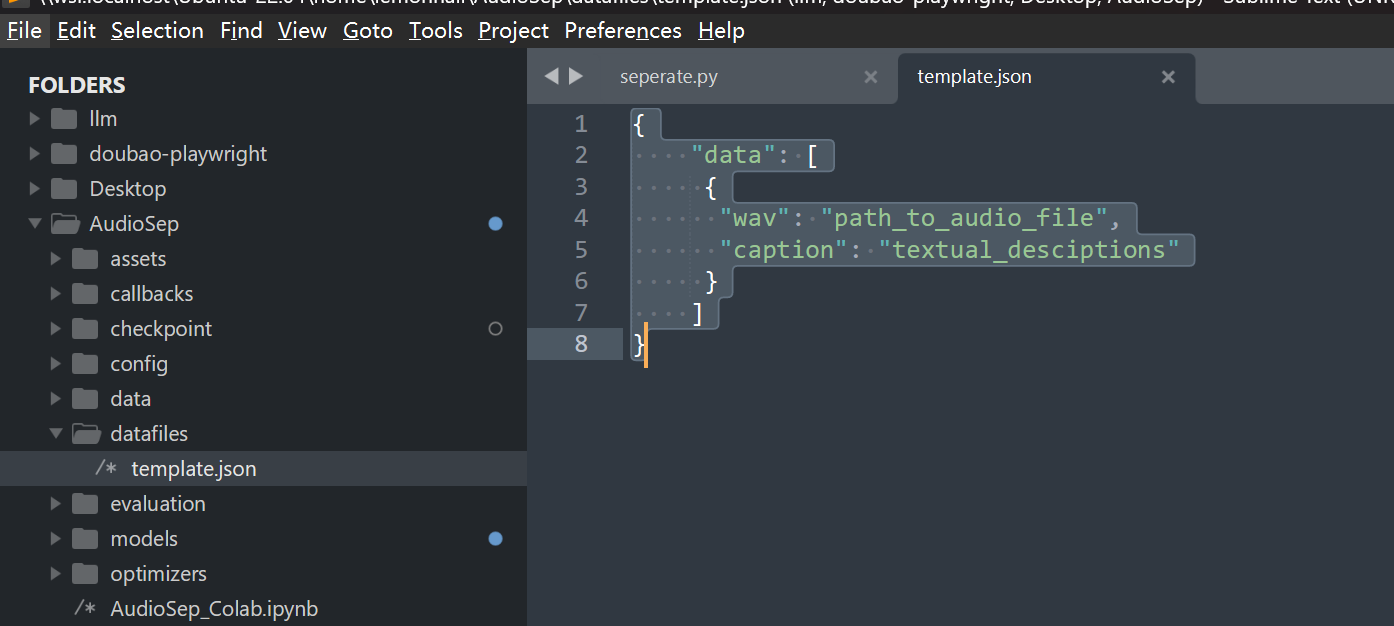
1、在datafiles里面
新建一个json文件
cd datafiles/
ffmpeg -i test_speech.mp3 lemonhall.wav之前咱不是有一个mp3文件么,用ffmpeg给转换成wav去
{
"data": [
{
"wav": "/home/lemonhall/AudioSep/datafiles/lemonhall.wav",
"caption": "lemonhall"
}
]
}然后json文件的内容也给它准备好
命名为:lemonhall.json
2、然后改个配置文件出来
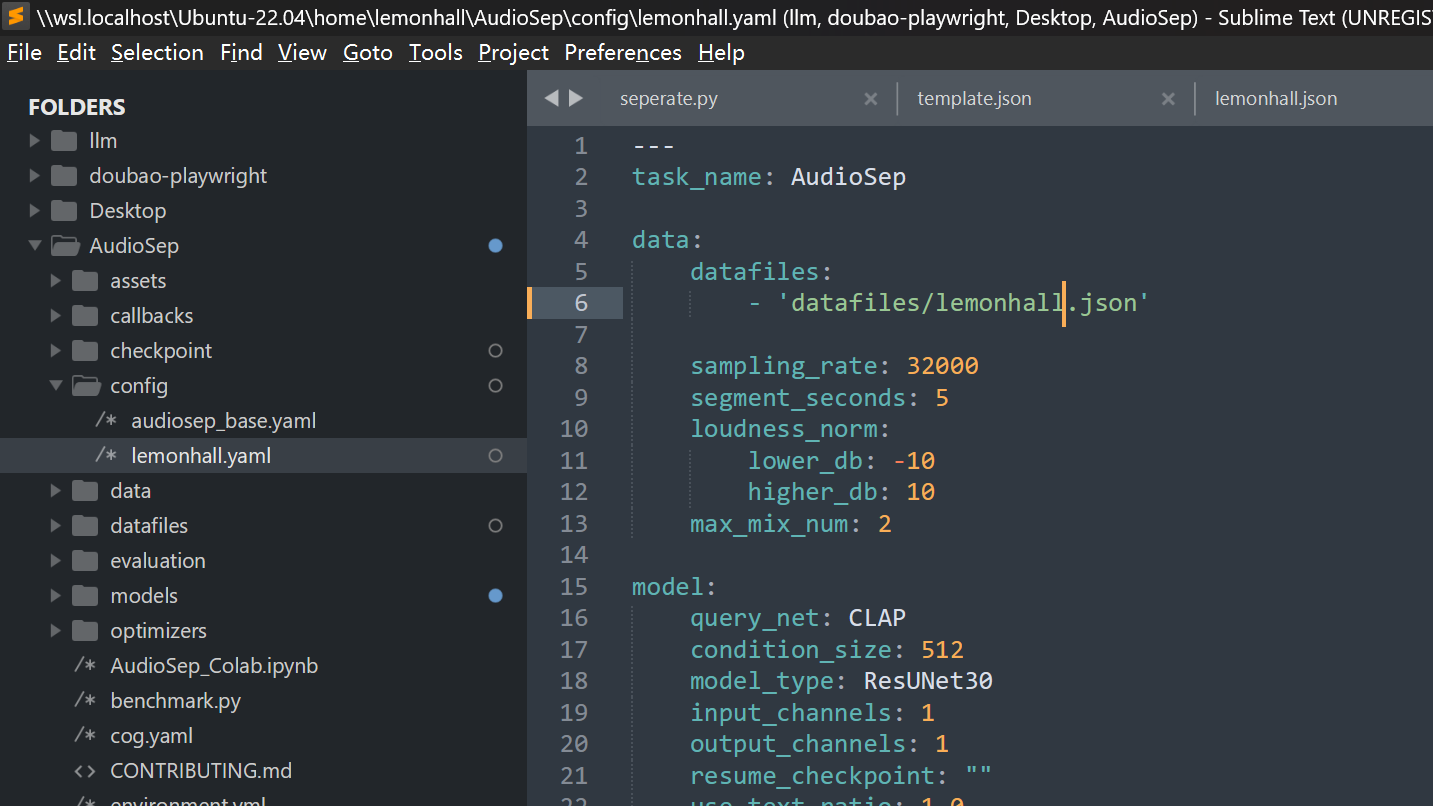
复制粘贴audiosep_base.yaml
之后就简单改一下里面的datafiles的具体json文件名
3、构造命令行训练:
python train.py --workspace workspace/AudioSep --config_yaml config/audiosep_base.yaml --resume_checkpoint_path path_to_checkpoint新建一个目录
mkdir workspacepython train.py --workspace workspace/AudioSep --config_yaml config/lemonhall.yaml --resume_checkpoint_path path_to_checkpoint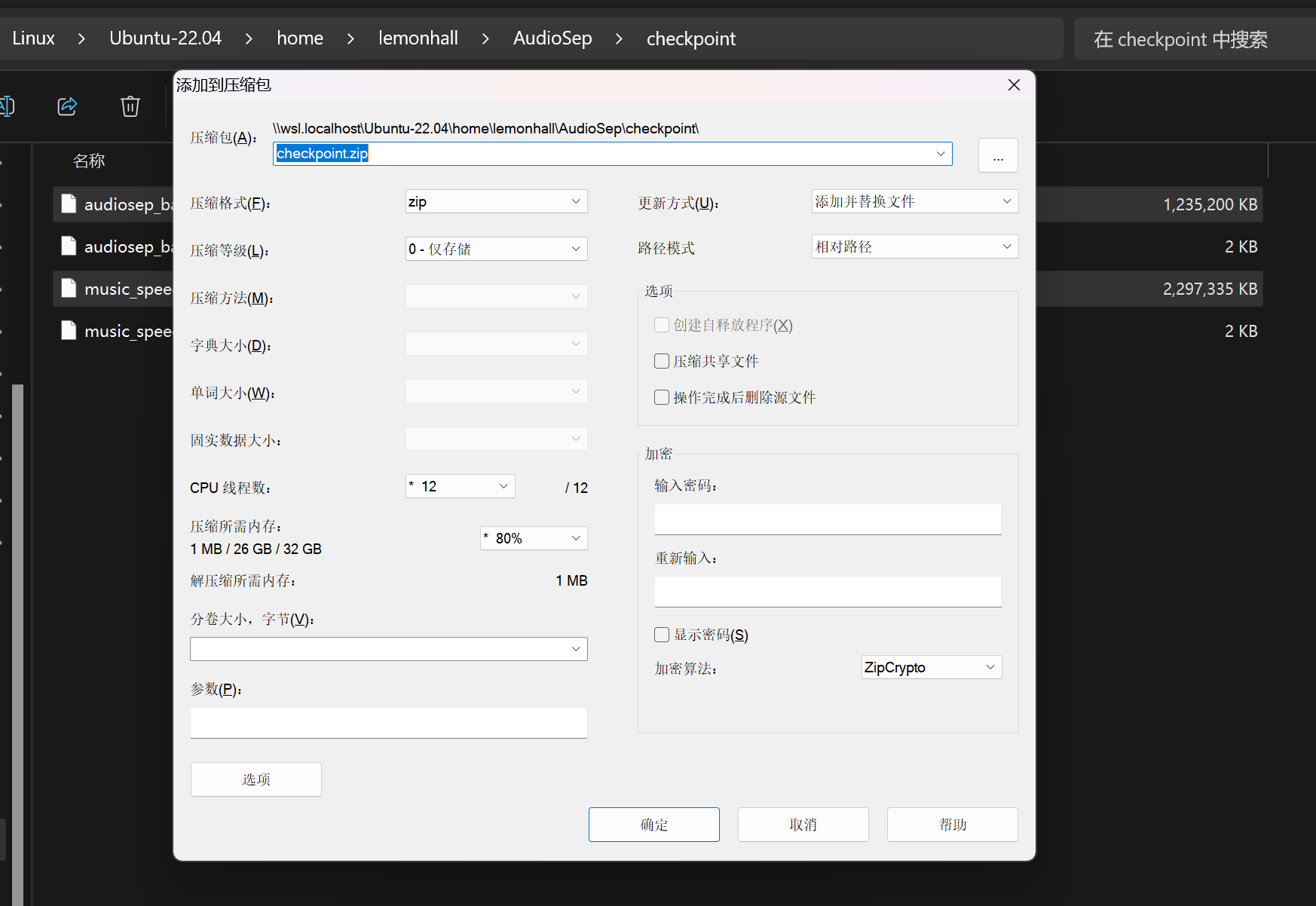
把这两个文件做一个仅存储的备份
python train.py --workspace workspace/AudioSep --config_yaml config/lemonhall.yaml --resume_checkpoint_path /home/lemonhall/AudioSep/checkpoint/audiosep_base_4M_steps.ckpt备份完成之后就开始增量的train一下试试
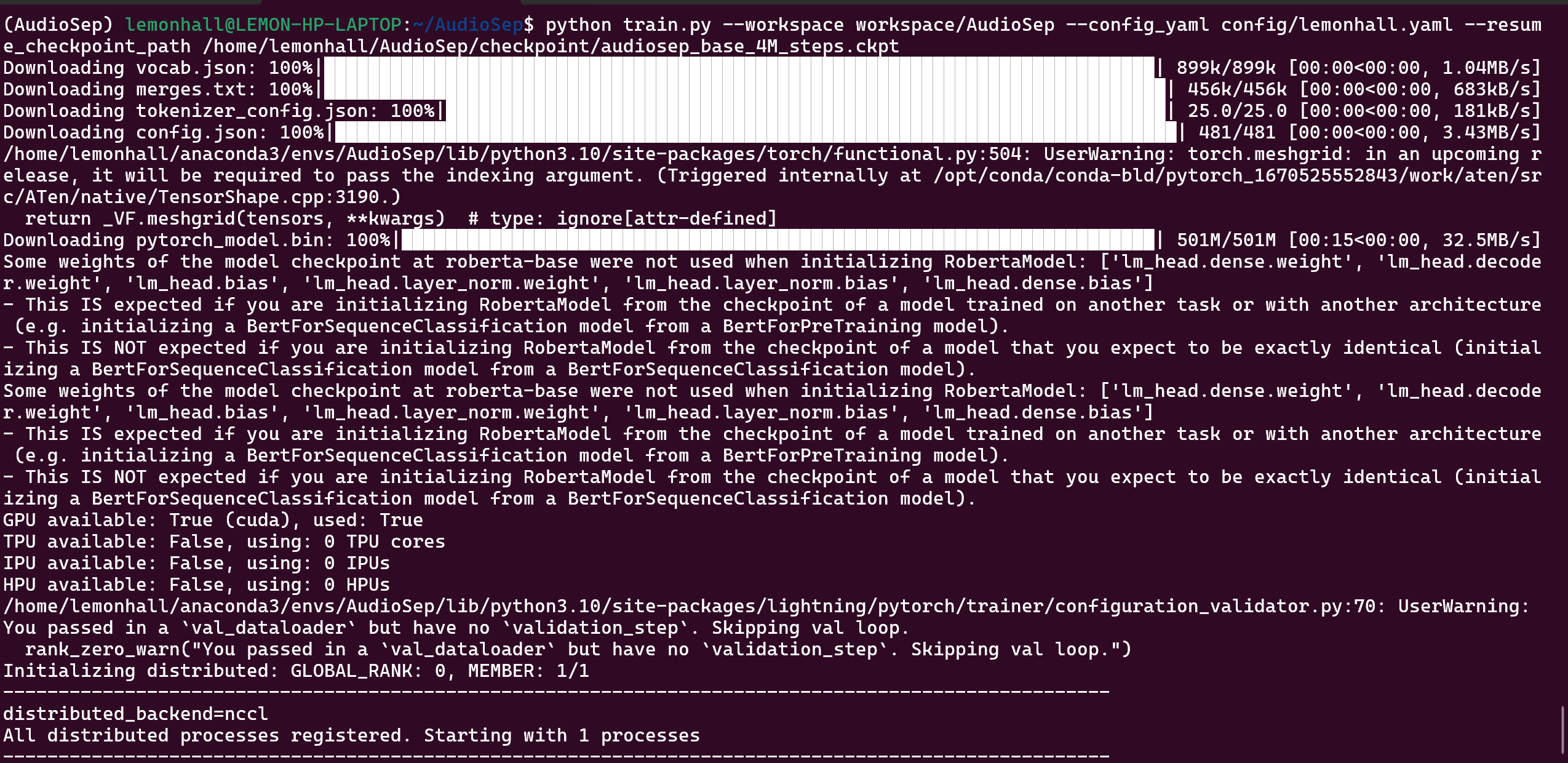
下载了许多的基础骨架
然后找到了GPU
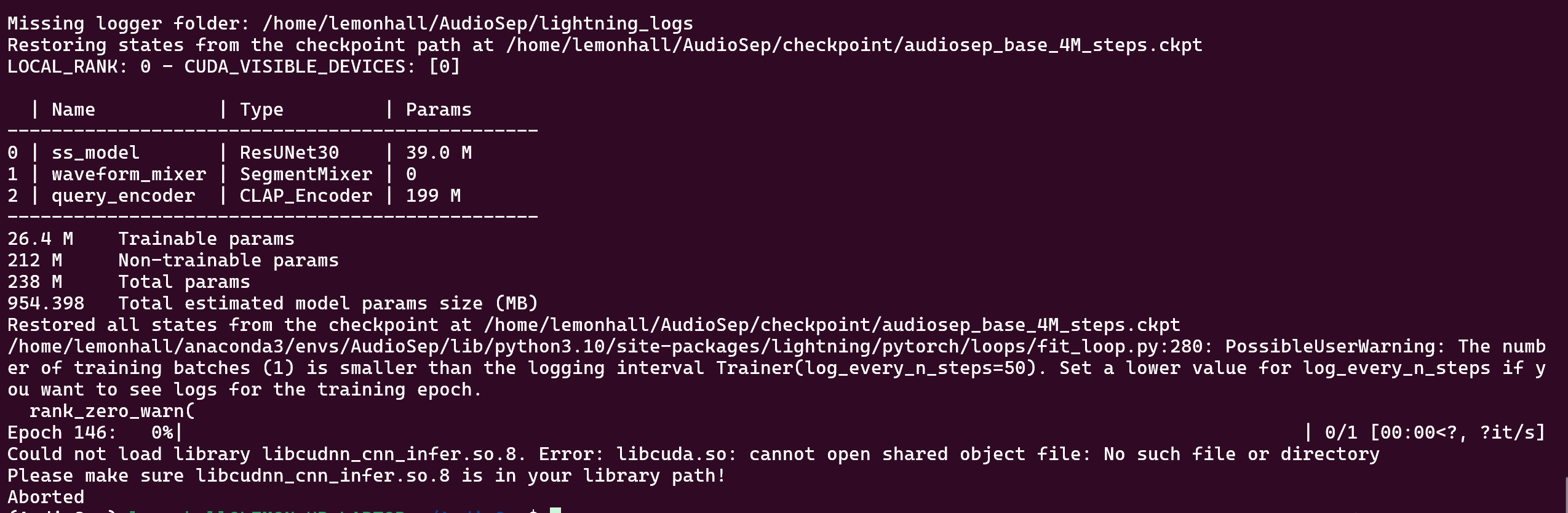
ok,这个库的作者真是略微有点小坑
报错了,cudnn_cnn_infer这边,说是没有libcuda.so这个库?
https://discuss.pytorch.org/t/libcudnn-cnn-infer-so-8-library-can-not-found/164661
我运行了:
ldconfig -p | grep cuda
证明了确实是安装了的
在bashrc里
export LD_LIBRARY_PATH=/usr/lib/wsl/lib:$LD_LIBRARY_PATH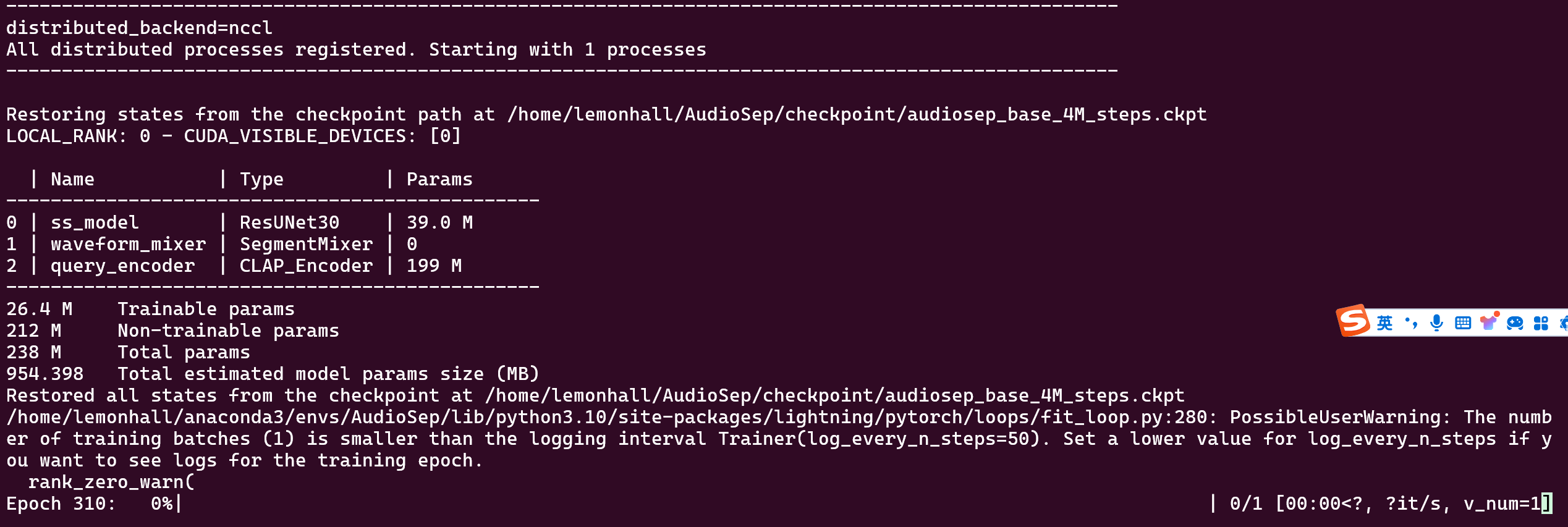
好了,错怪作者了,这是个wsl2特有的坑