1、环境:
mkdir tts
cd tts
python3 -m venv .venv
source .venv/bin/activate2、安装
https://github.com/coqui-ai/TTS
pip install TTS6.3G呢,别着急
3、跑实际的语音clone
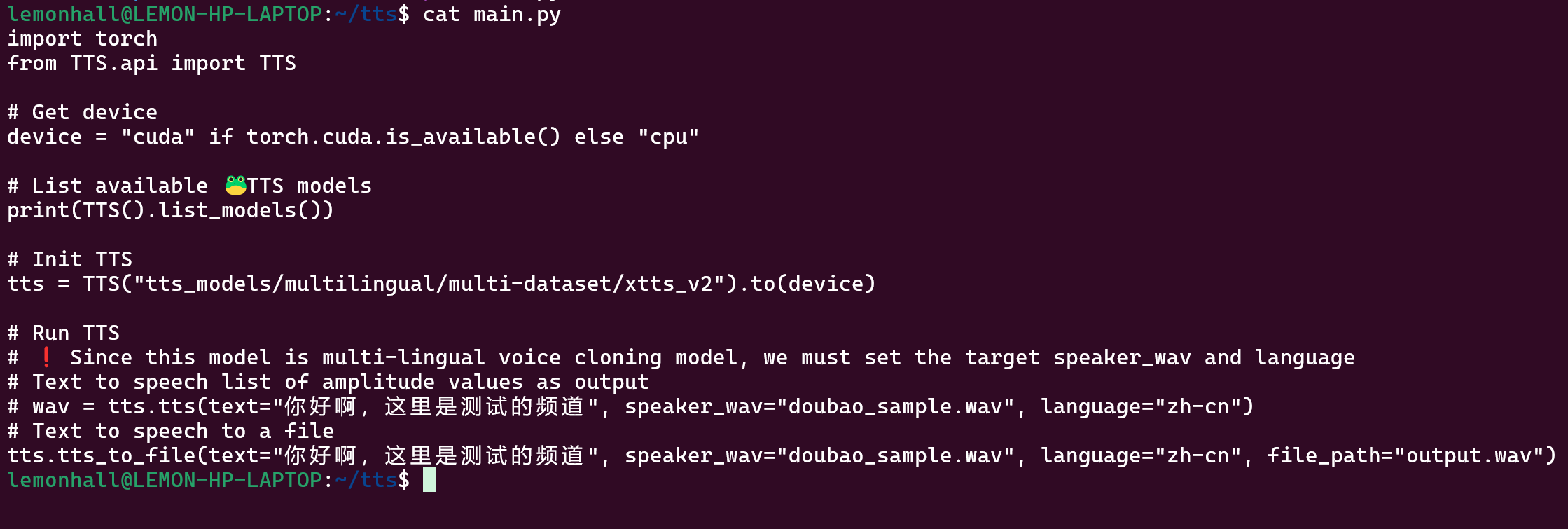
import torch
from TTS.api import TTS
# Get device
device = "cuda" if torch.cuda.is_available() else "cpu"
# List available 🐸TTS models
print(TTS().list_models())
# Init TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to(device)
# Run TTS
# ❗ Since this model is multi-lingual voice cloning model, we must set the target speaker_wav and language
# Text to speech list of amplitude values as output
wav = tts.tts(text="Hello world!", speaker_wav="my/cloning/audio.wav", language="en")
# Text to speech to a file
tts.tts_to_file(text="Hello world!", speaker_wav="my/cloning/audio.wav", language="en", file_path="output.wav")官方例子别管他
sample是用豆包的语音
ffmpeg -i input.mp4 output.wav用命令转换出来的
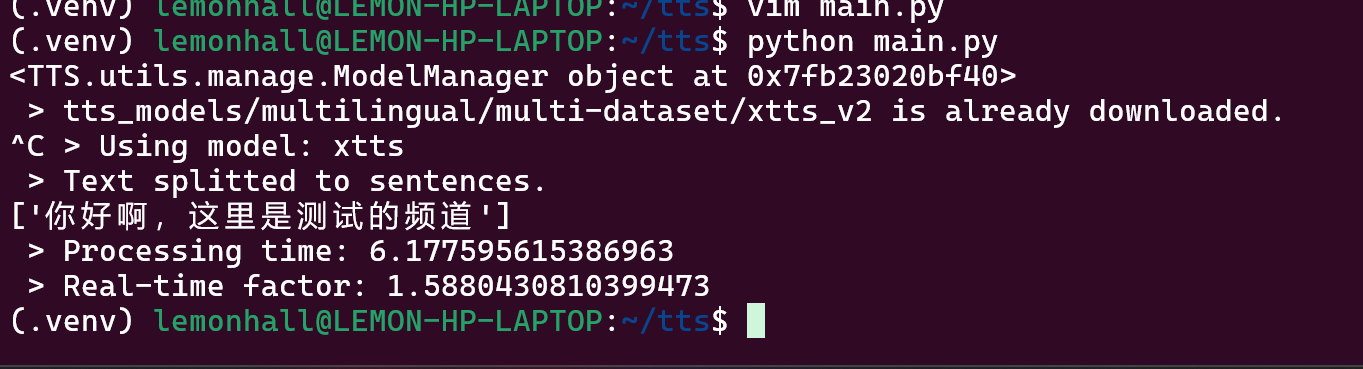
好了,跑出来了
4、TODO
跑出来了,但是其实非常的慢
我感觉第一是我给的sample的声音有点过长了,给个6秒的就够了,官方也说了
第二是,这个框架我感觉就是故意的
第三是,它本身还有一个server版本
明天看看