https://docs.coqui.ai/en/latest/inference.html
根据文档内容:
激活环境:
cd tts
python3 -m venv .venv
source .venv/bin/activate列出所有的模型:
tts --list_models Name format: type/language/dataset/model
1: tts_models/multilingual/multi-dataset/xtts_v2 [already downloaded]
2: tts_models/multilingual/multi-dataset/xtts_v1.1
3: tts_models/multilingual/multi-dataset/your_tts
4: tts_models/multilingual/multi-dataset/bark
5: tts_models/bg/cv/vits
6: tts_models/cs/cv/vits
7: tts_models/da/cv/vits
8: tts_models/et/cv/vits
9: tts_models/ga/cv/vits
10: tts_models/en/ek1/tacotron2
11: tts_models/en/ljspeech/tacotron2-DDC
12: tts_models/en/ljspeech/tacotron2-DDC_ph
13: tts_models/en/ljspeech/glow-tts
14: tts_models/en/ljspeech/speedy-speech
15: tts_models/en/ljspeech/tacotron2-DCA
16: tts_models/en/ljspeech/vits
17: tts_models/en/ljspeech/vits--neon
18: tts_models/en/ljspeech/fast_pitch
19: tts_models/en/ljspeech/overflow
20: tts_models/en/ljspeech/neural_hmm
21: tts_models/en/vctk/vits
22: tts_models/en/vctk/fast_pitch
23: tts_models/en/sam/tacotron-DDC
24: tts_models/en/blizzard2013/capacitron-t2-c50
25: tts_models/en/blizzard2013/capacitron-t2-c150_v2
26: tts_models/en/multi-dataset/tortoise-v2
27: tts_models/en/jenny/jenny
28: tts_models/es/mai/tacotron2-DDC
29: tts_models/es/css10/vits
30: tts_models/fr/mai/tacotron2-DDC
31: tts_models/fr/css10/vits
32: tts_models/uk/mai/glow-tts
33: tts_models/uk/mai/vits
34: tts_models/zh-CN/baker/tacotron2-DDC-GST
35: tts_models/nl/mai/tacotron2-DDC
36: tts_models/nl/css10/vits
37: tts_models/de/thorsten/tacotron2-DCA
38: tts_models/de/thorsten/vits
39: tts_models/de/thorsten/tacotron2-DDC
40: tts_models/de/css10/vits-neon
41: tts_models/ja/kokoro/tacotron2-DDC
42: tts_models/tr/common-voice/glow-tts
43: tts_models/it/mai_female/glow-tts
44: tts_models/it/mai_female/vits
45: tts_models/it/mai_male/glow-tts
46: tts_models/it/mai_male/vits
47: tts_models/ewe/openbible/vits
48: tts_models/hau/openbible/vits
49: tts_models/lin/openbible/vits
50: tts_models/tw_akuapem/openbible/vits
51: tts_models/tw_asante/openbible/vits
52: tts_models/yor/openbible/vits
53: tts_models/hu/css10/vits
54: tts_models/el/cv/vits
55: tts_models/fi/css10/vits
56: tts_models/hr/cv/vits
57: tts_models/lt/cv/vits
58: tts_models/lv/cv/vits
59: tts_models/mt/cv/vits
60: tts_models/pl/mai_female/vits
61: tts_models/pt/cv/vits
62: tts_models/ro/cv/vits
63: tts_models/sk/cv/vits
64: tts_models/sl/cv/vits
65: tts_models/sv/cv/vits
66: tts_models/ca/custom/vits
67: tts_models/fa/custom/glow-tts
68: tts_models/bn/custom/vits-male
69: tts_models/bn/custom/vits-female
70: tts_models/be/common-voice/glow-tts
Name format: type/language/dataset/model
1: vocoder_models/universal/libri-tts/wavegrad
2: vocoder_models/universal/libri-tts/fullband-melgan
3: vocoder_models/en/ek1/wavegrad
4: vocoder_models/en/ljspeech/multiband-melgan
5: vocoder_models/en/ljspeech/hifigan_v2
6: vocoder_models/en/ljspeech/univnet
7: vocoder_models/en/blizzard2013/hifigan_v2
8: vocoder_models/en/vctk/hifigan_v2
9: vocoder_models/en/sam/hifigan_v2
10: vocoder_models/nl/mai/parallel-wavegan
11: vocoder_models/de/thorsten/wavegrad
12: vocoder_models/de/thorsten/fullband-melgan
13: vocoder_models/de/thorsten/hifigan_v1
14: vocoder_models/ja/kokoro/hifigan_v1
15: vocoder_models/uk/mai/multiband-melgan
16: vocoder_models/tr/common-voice/hifigan
17: vocoder_models/be/common-voice/hifigan
Name format: type/language/dataset/model
1: voice_conversion_models/multilingual/vctk/freevc24反正分成了tts模型和vocder模型
具体是啥我也不知道
我其实是在用这个:
1: tts_models/multilingual/multi-dataset/xtts_v2 [already downloaded]然后我感觉效果一般:
所以我改了一下默认的程序:
34: tts_models/zh-CN/baker/tacotron2-DDC-GST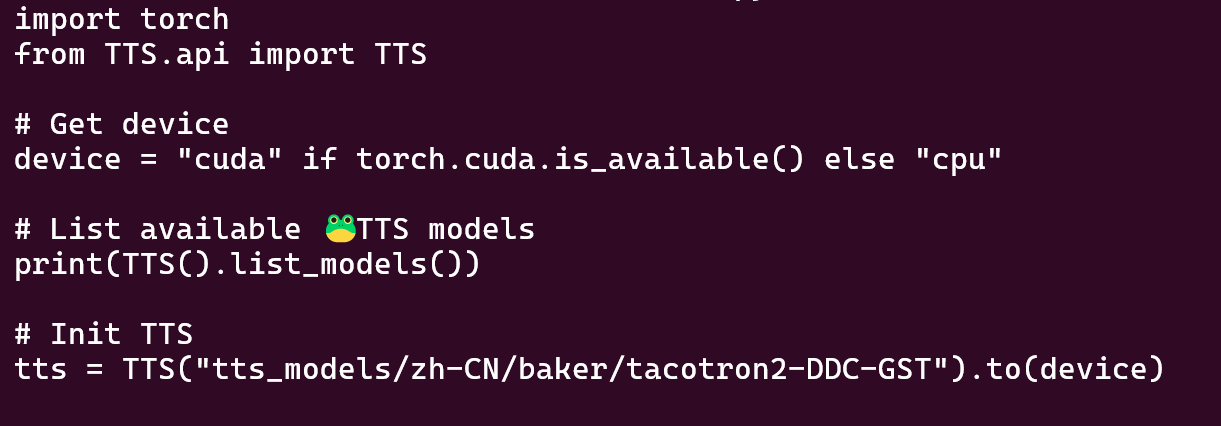
试试效果

它每一个模型都不小,就每一个省心的
又是一个700MB的模型

程序直接报错
嗯,所以删掉language那个参数就可以了
跑出来的效果也一般
因为这个模型有一个严重的压缩音质的感觉
感觉电音也挺强的,哈哈哈哈
还行吧,我再试试别人的声音
但,比起主模型有一个明显的优点,那就是.....不是台湾腔
但我也可以去试试指定台湾腔会怎样
不过如果用这个模型,推理速度倒是超级快