1、建立环境
python3 -m venv .venv
source .venv/bin/activate2、注册账号
https://rapidapi.com/nguyenmanhict-MuTUtGWD7K/api/douyin-media-no-watermark1
3、拷贝代码
import requests
url = "https://douyin-media-no-watermark1.p.rapidapi.com/v1/social/douyin/web/aweme/detail"
payload = { "id": "7359535799487974710" }
headers = {
"content-type": "application/json",
"X-RapidAPI-Key": "xxxxxxxxxxxxxxxxxxxxxxx",
"X-RapidAPI-Host": "douyin-media-no-watermark1.p.rapidapi.com"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())4、安装依赖
pip install requests5、修改默认脚本
import requests
def getDownladUrlById(id):
url = "https://douyin-media-no-watermark1.p.rapidapi.com/v1/social/douyin/web/aweme/detail"
payload = { "id": id }
headers = {
"content-type": "application/json",
"X-RapidAPI-Key": "xxxxxxxxxxxxxxxxxxx",
"X-RapidAPI-Host": "douyin-media-no-watermark1.p.rapidapi.com"
}
response = requests.post(url, json=payload, headers=headers)
respJson = response.json()
#第一级:aweme_detail
#第一级下第一级子属性:desc:"desc": "钢铁侠片段中的小细节 #漫威 #钢铁侠 #电影解说"
#第一季下第一级子鼠星:video
#video下子属性:cover,cover是一个{}对象,对象里的属性之一,url_list,是一个[],这个列表里的第一个属性是一个url,是封面
#同理,video下的子属性,download_addr,是一个{}对象,对象里面又有一个,url_list,是一个[],第一个是一个地址
#https://blog.csdn.net/xuaner8786/article/details/136294988
videoDesc = respJson['aweme_detail']['desc']
video = respJson['aweme_detail']['video']
videoCover = video['cover']['url_list'][0]
videoUrl = video['download_addr']['url_list'][0]
# print("1、视频标题:",videoDesc)
# print("2、视频封面:")
# print(videoCover)
# print("3、视频下载地址:")
# print(videoUrl)
res = {"videoDesc":videoDesc,"videoCover":videoCover,"videoUrl":videoUrl}
return res
def downloadVideo(url,filename):
response =requests.get(url,stream=True)
response.raise_for_status()
with open(filename,"wb") as file:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
file.write(chunk)
if __name__ == "__main__":
result = getDownladUrlById("7359535799487974710")
print(result['videoDesc'])
downloadVideo(result['videoUrl'],"7359535799487974710.mp4")OK,这就妥了
然后是API化,交给前端的js去调用?
6、然后是前端取这个当前视频id的代码,我也通过元素搜索的方式找到了
let videoInfoDetailElement = document.querySelector('.video-info-detail');
let dataId = videoInfoDetailElement.getAttribute('data-e2e-aweme-id');
console.log(dataId);还是豆包帮我写的
7、先把python这边http化掉:
安装个依赖:
pip install FastAPIfrom fastapi import FastAPI
app = FastAPI()
@app.get("/video/{video_id}")
async def get_video(video_id: int):
# 在这里处理视频 ID,例如查询数据库或其他操作
return {"message": f"视频 ID: {video_id}"}然后我让豆包帮我写了个架子
然后安装服务器启动依赖
pip install uvicornuvicorn server:app --reload然后这么启动
server.py是我的文件名哈
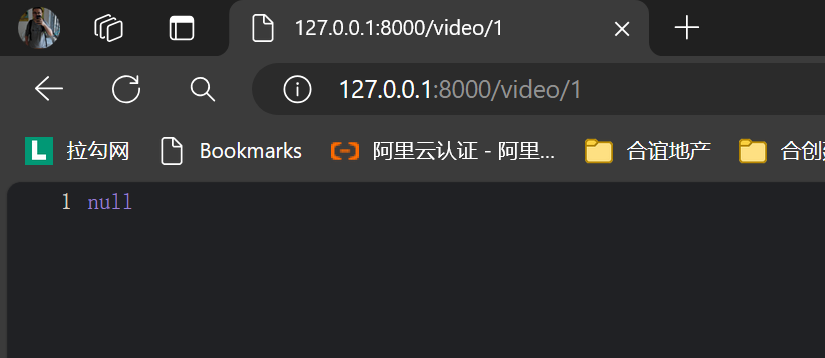
这么访问了一下是O的
然后我又试了一下:
http://127.0.0.1:8000/video/7358439905023905039
感觉有有点小问题,download那部分应该改成async的
先不管了,稍后优化
8、接下来写油猴脚本
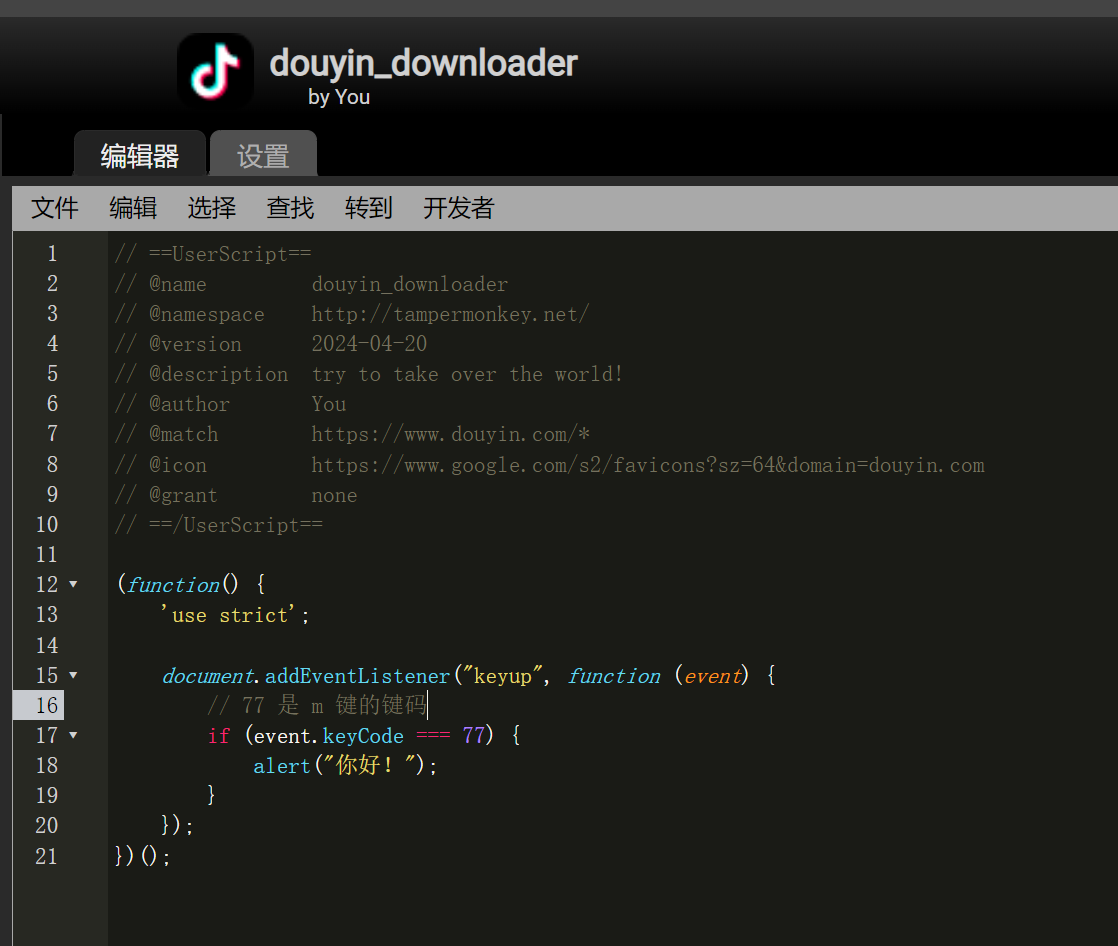
// ==UserScript==
// @name douyin_downloader
// @namespace http://tampermonkey.net/
// @version 2024-04-20
// @description try to take over the world!
// @author You
// @match https://www.douyin.com/*
// @icon https://www.google.com/s2/favicons?sz=64&domain=douyin.com
// @grant none
// ==/UserScript==
(function() {
'use strict';
document.addEventListener("keyup", function (event) {
// 77 是 m 键的键码
if (event.keyCode === 77 || event.keyCode === 109) {
let videoInfoDetailElement = document.querySelector('.video-info-detail');
let dataId = videoInfoDetailElement.getAttribute('data-e2e-aweme-id');
console.log(dataId);
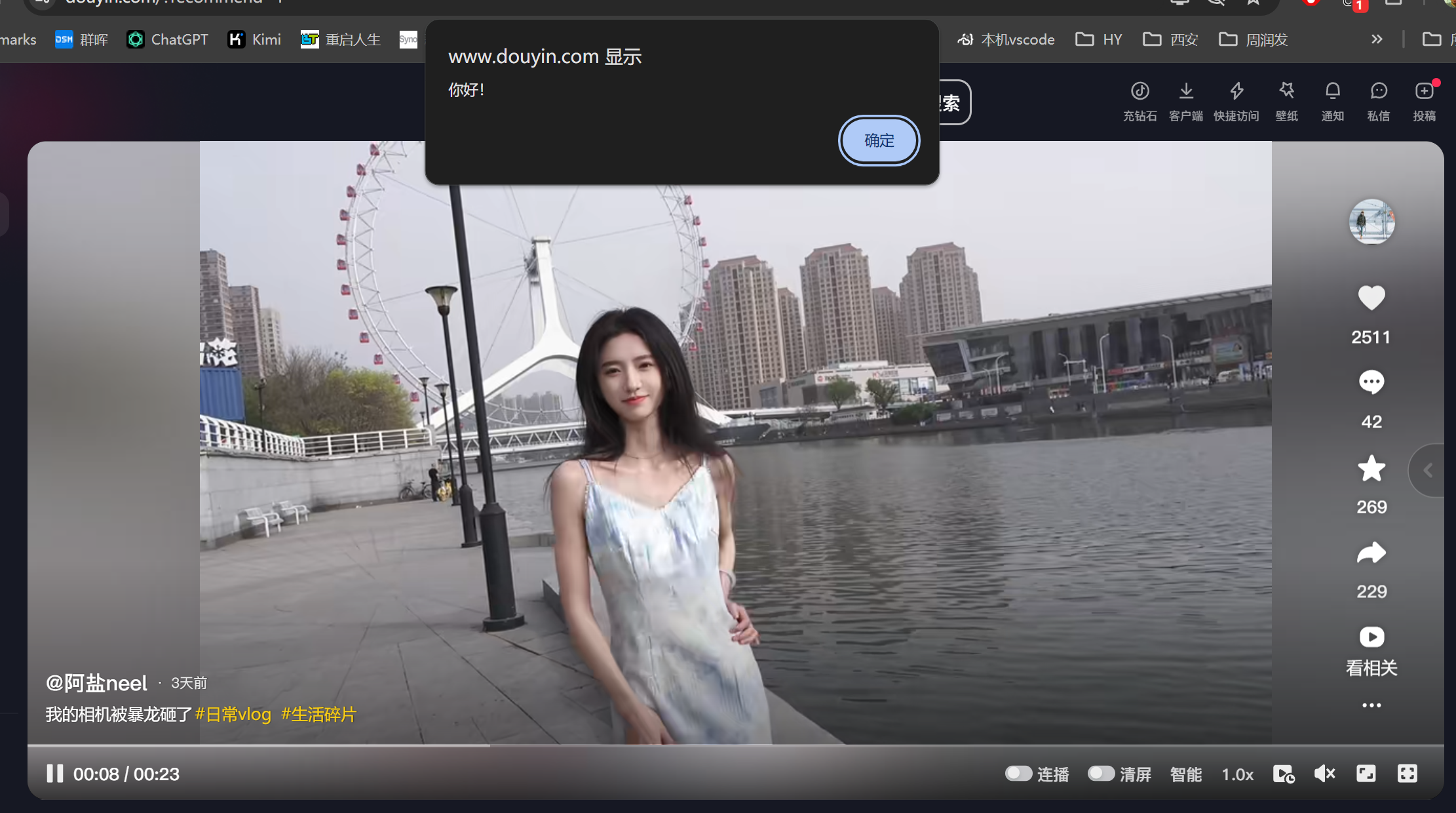
alert("你好!"+dataId);
fetch("http://127.0.0.1:8000/video/"+dataId).then(response => response.json()).then(data => console.log(data));
}
});
})();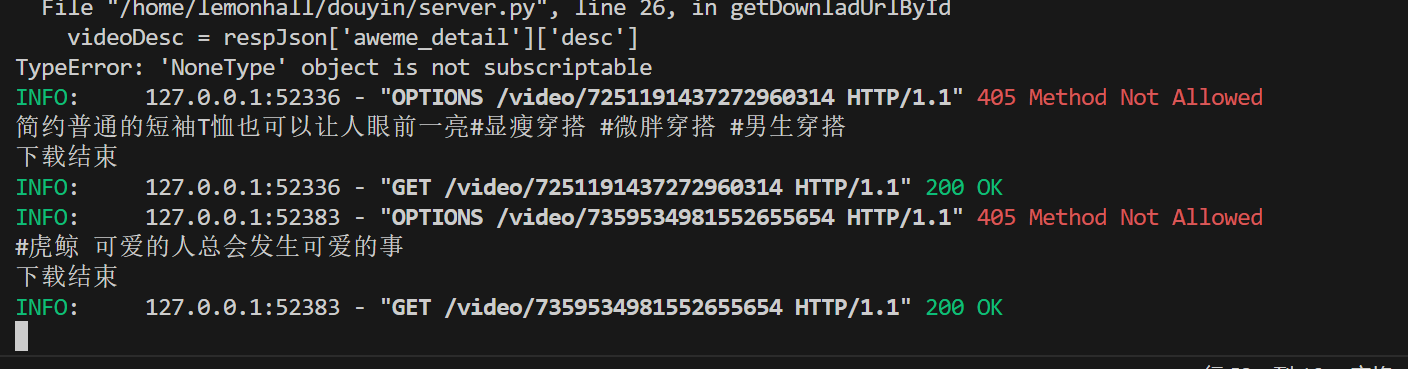
嗯嗯,下载成功,挺好
这个脚本python因为依赖很少
所以也可以简单的docker化之后部署到nas那边去