参考文章: https://blog.lemonhall.me/notesview/show/490
1、环境
mkdir llama38b
cd llama38b/
python3 -m venv .venv
source .venv/bin/activate2、安装依赖
pip install huggingface-hub3、下载模型
mkdir downloadshuggingface-cli download \
PrunaAI/Llama3-8B-Chinese-Chat-GGUF-smashed \
Llama3-8B-Chinese-Chat.Q6_K.gguf \
--local-dir downloads \
--local-dir-use-symlinks False依照经验,我用了Q6的

大约5分钟吧,等一等
然后是参考上次的那个坑: https://blog.lemonhall.me/notesview/show/491
因为官方实际上是由llama3的
https://ollama.com/library/llama3
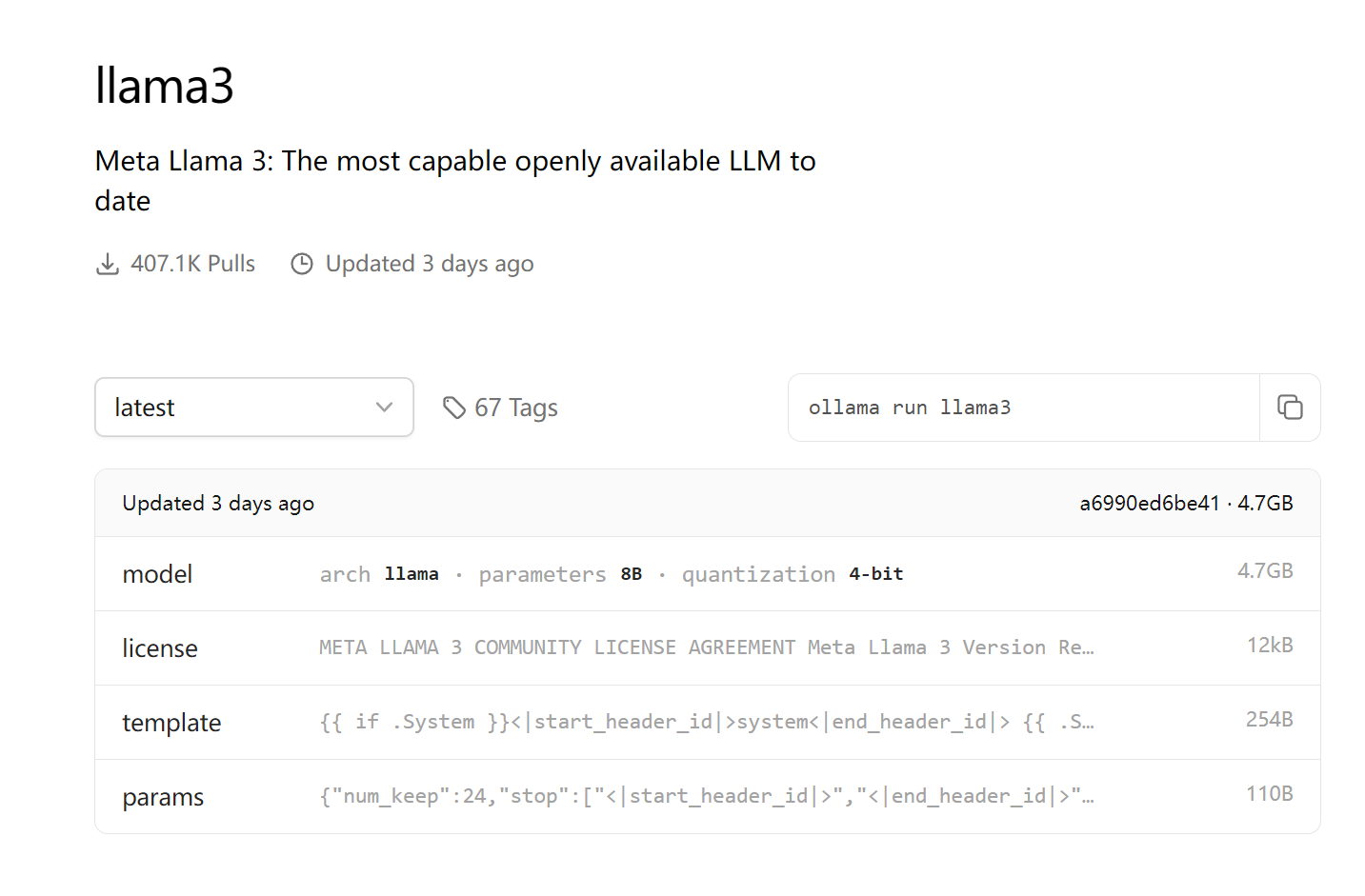
所以人家是既有参数又有模板
https://github.com/ollama/ollama/blob/main/docs/modelfile.md#build-from-llama2
FROM "./downloads/causallm_7b-dpo-alpha.Q8_0.gguf"
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|im_end|>"
TEMPLATE """
<|im_start|>system
{{ .System }}<|im_end|>
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""参考之前的,再写一个

vim Modelfile# Modelfile
FROM "./downloads/Llama3-8B-Chinese-Chat.Q6_K.gguf"
PARAMETER num_keep 24
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
TEMPLATE """
{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>
"""以上的模板和参数等于我直接参考了正版的Llama3的仓库里的文件
4、创建模型哈
ollama create llama38bChineseQ6k -f Modelfile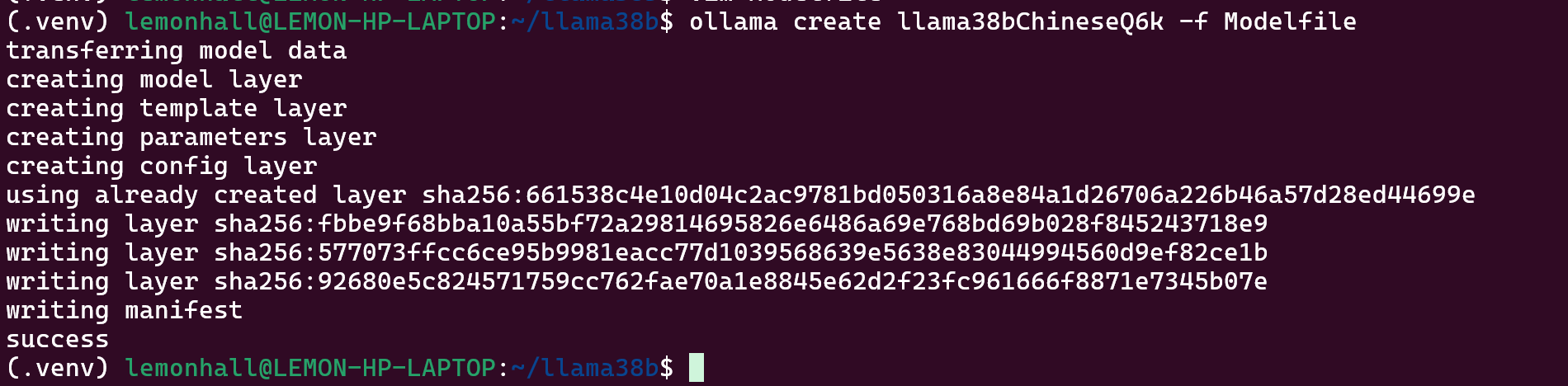
成功跑出来了
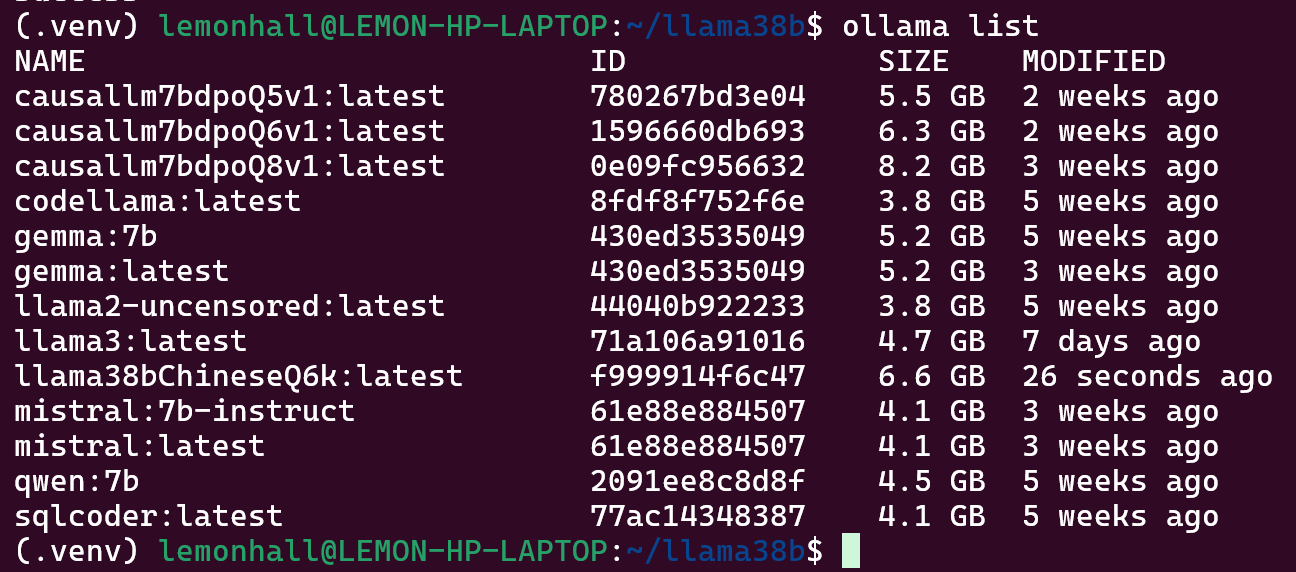
ollama run llama38bChineseQ6k运行模型

ok,可以了
其实这不是一个完全解码的版本
但起码中文说的不错,就行了
先这样,稍后玩玩