其实我玩了一下OpenAI那边的Wisper的ASR,效果是不错,但是语音分离技术上让人很抓狂
然后也玩过声音Clone的几个模型,效果其实都一般,我其实很想要GPT的TTS技术
另外今天还刷到一个叫ChatTTS的项目,稍后再去试吧
今天试试这个,GPT-SoVITS,这个是B站的死宅们用得最多的一个
1、零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
2、少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
3、跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
4、WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。我看了一下功能,卧槽
真的是死宅们爱是有道理的啊
装装看
https://github.com/RVC-Boss/GPT-SoVITS/blob/main/docs/cn/README.md
===================================

我现在都不爱用conda啊python的venv环境安装这些东西,因为十分容易损坏(其实还是因为我自己习惯也不好,经常喜欢更新系统)
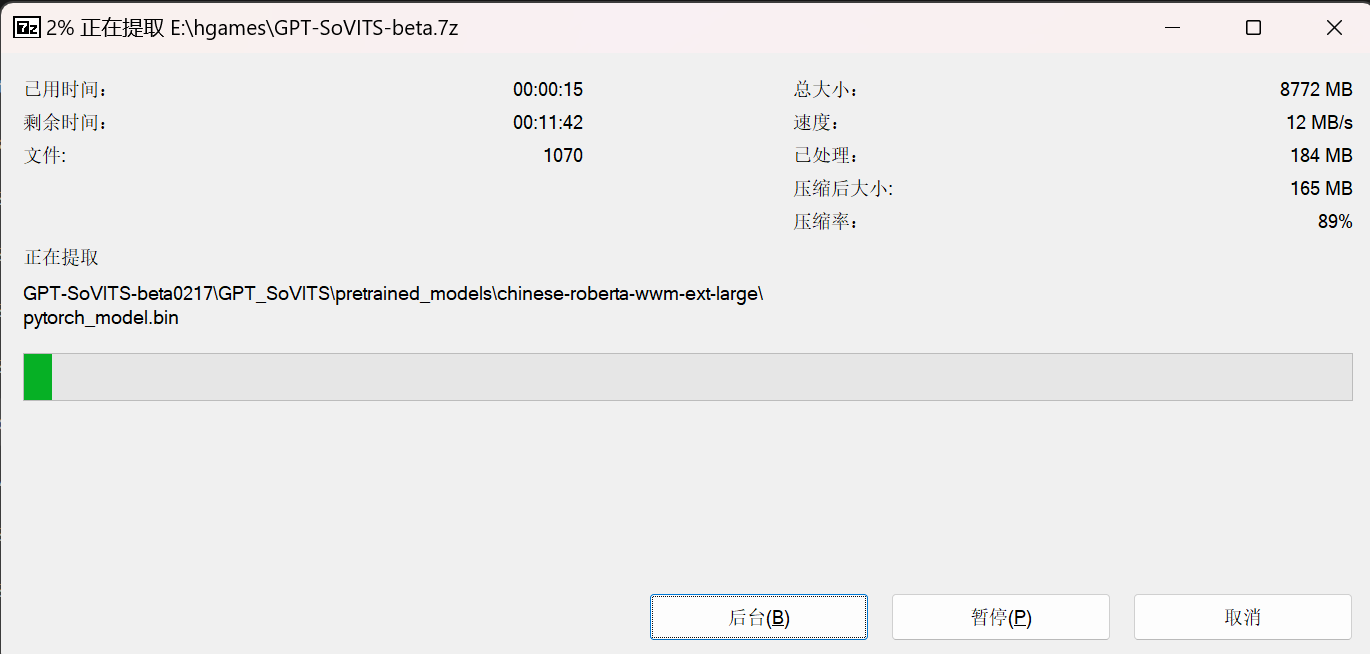
解压,也能看得出来,这实际上是0217版本的

所以我,最终选择了下载0306版本
又是4G
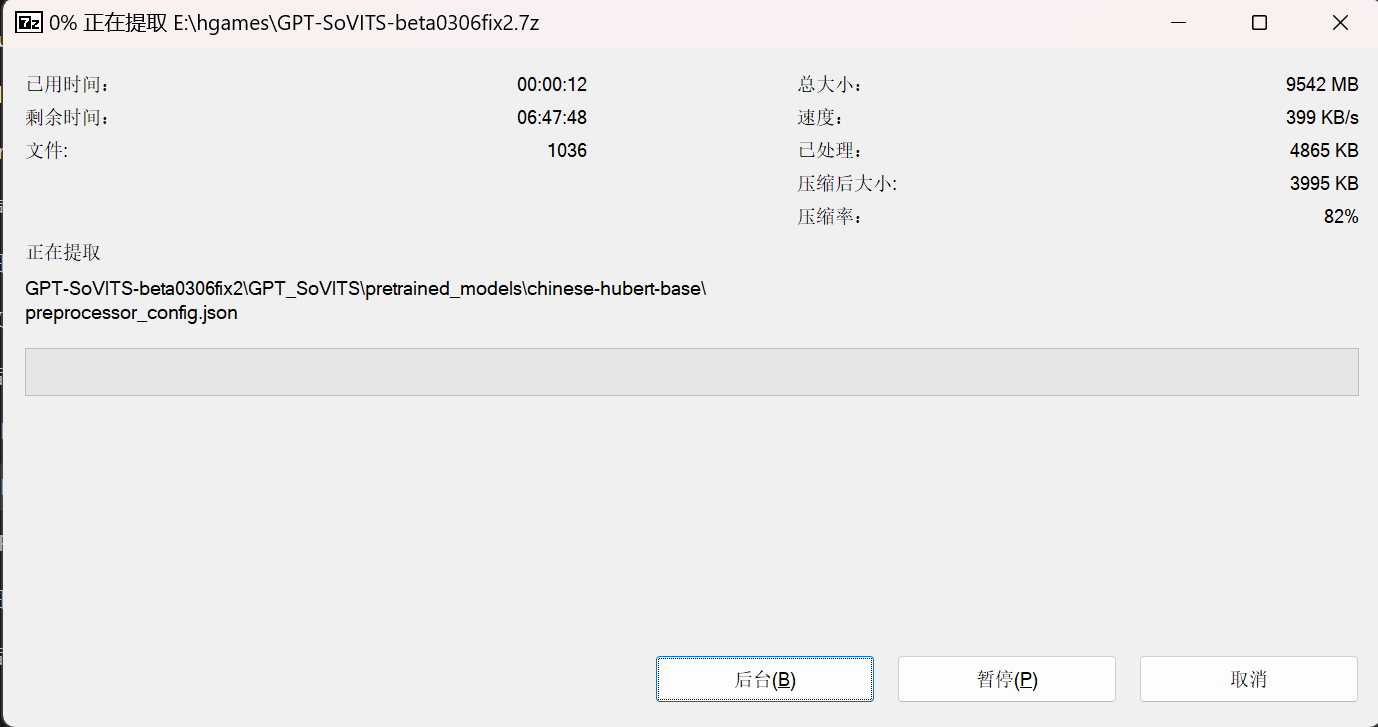
我得天啊,10个G的大小,这应该是所有的模型都含进去了
否则这么大简直没天理
我心里一慌,赶紧把ComfyUI关掉了,真都是些耗能大户呗
go-webui.bat
看了一下哈,这个整合包里模型这些基本都下载好了的,省心
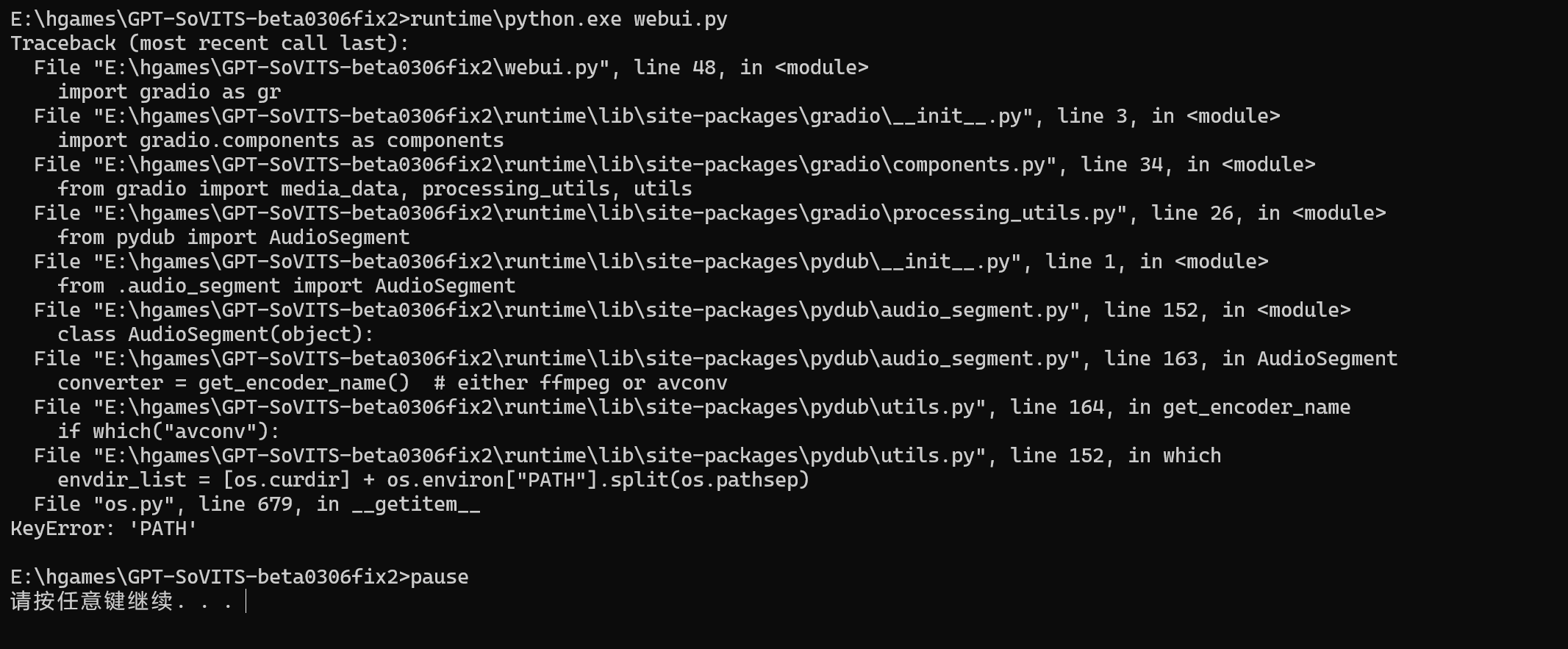
哎呦喂
报错哎,真不靠谱,算了,明天再说