import torch
import pandas as pd
# 定义神经网络类
class AudioClassifier(torch.nn.Module):
def __init__(self, batch_size, in_features):
super(AudioClassifier, self).__init__()
self.layer1 = torch.nn.Linear(in_features, 128)
self.additional_layer = torch.nn.Linear(128, 64)
self.layer2 = torch.nn.Linear(64, 32)
self.layer3 = torch.nn.Linear(32, 2) # 假设两类
def forward(self, x):
x = torch.relu(self.layer1(x))
x = torch.relu(self.additional_layer(x)) # 使用新增层
x = torch.relu(self.layer2(x))
x = self.layer3(x)
return x
# 读取数据并处理
def load_data(file_paths):
data = []
labels = []
for path in file_paths:
df = pd.read_csv(path, skiprows=1) # 跳过第一行
features = df.values
data.append(features)
# 根据文件名确定标签
if "c0" in path:
labels.append(0)
elif "c1" in path:
labels.append(1)
return torch.tensor(data), torch.tensor(labels)
# 示例用法
train_file_paths = ["traindata_c0_1.csv","traindata_c0_2.csv","traindata_c0_3.csv","traindata_c0_4.csv"
,"traindata_c0_5.csv","traindata_c0_6.csv","traindata_c0_11.csv","traindata_c0_12.csv",
"traindata_c0_13.csv","traindata_c0_14.csv","traindata_c0_15.csv","traindata_c0_16.csv",
"traindata_c0_17.csv","traindata_c0_18.csv","traindata_c0_19.csv","traindata_c0_20.csv",
"traindata_c0_21.csv","traindata_c0_22.csv",
"traindata_c1_1.csv","traindata_c1_2.csv","traindata_c1_3.csv","traindata_c1_4.csv"
,"traindata_c1_5.csv","traindata_c1_6.csv","traindata_c1_11.csv","traindata_c1_12.csv"
,"traindata_c1_13.csv","traindata_c1_14.csv","traindata_c1_15.csv","traindata_c1_16.csv"
,"traindata_c1_17.csv","traindata_c1_18.csv","traindata_c1_19.csv","traindata_c1_20.csv"]
train_data, train_labels = load_data(train_file_paths)
print("train_data.dtype:"+str(train_data.dtype))
print("train_labels.dtype:"+str(train_labels.dtype))
# 创建神经网络
# 对于 torch.nn.Linear,它通常期望输入的是一个二维张量,
# 其中第一维可以理解为批量大小(在你的例子中就是 20 个样本),
# 第二维是每个样本的特征数量。在你这个情况中,你需要先将每个样本(119 行×7 列)展平成一个一维向量,
# 这样每个样本就变成了一个长度为 119×7=833 的向量。然后将这 20 个展平后的样本组合成一个二维张量,
# 其形状就是 (20, 833),将这个二维张量作为输入传递给 torch.nn.Linear。
# 例如,如果有一个输入张量x,其形状为[batch_size, in_features],
# 那么经过Linear层的变换后,输出张量y的形状将为[batch_size, out_features]。
num_of_samples = train_data.size(0)
num_of_rows = train_data[0].shape[0]
num_of_cols = train_data[0].shape[1]
print("num_of_samples:")
print(num_of_samples)
print("num_of_rows:")
print(num_of_rows)
print("num_of_cols:")
print(num_of_cols)
model = AudioClassifier(num_of_samples,num_of_rows*num_of_cols)
# 要保持原始张量的维度顺序不变,可以使用permute方法进行维度变换。
# permute方法接受一个参数,用于指定新的维度顺序。例如,如果你想将最后两维展平,可以使用以下代码:
# 上面说法根本就是错的,需要用到reshape方法,把张量reshape成一个[batch_size, in_features]的东西
new_train_data_tensor = train_data.reshape(num_of_samples, 119*7)
print("new_train_data_tensor shape:")
print(new_train_data_tensor.shape) # 输出新张量的形状
# 定义损失函数和优化器
loss_func = torch.nn.CrossEntropyLoss()
criterion = torch.nn.BCELoss() # 使用默认参数
optimizer = torch.optim.Adam(model.parameters())
print("=========tow input shapes=============")
print(new_train_data_tensor.shape, train_labels.shape)
print("=========tow input shapes=============")
# 训练循环
for epoch in range(200):
outputs = model(new_train_data_tensor.to(torch.float32))
#outputs = torch.sigmoid(outputs) # 应用sigmoid函数确保输出在0和1之间
loss = loss_func(outputs, train_labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("==========outputs.shape:============")
print(outputs.shape)
# print("==========outputs:============")
# print(outputs)
# ==========outputs:============
# tensor([[ 10.3342, -3.6685],
# [ 13.9501, -0.4912],
# [ 15.0824, -1.4321],
# [ 16.4281, -1.1477],
# [ 11.7916, -4.5559],
# [ 15.0455, -5.4270],
# [ 10.3306, -8.4917],
# [ 9.7162, -8.0242],
# [ 11.2048, -7.3689],
# [ 6.1282, -6.2711],
# [ -3.8303, 7.0840],
# [ -4.3532, 17.0647],
# [-15.7246, 44.2592],
# [ -7.8866, 12.5852],
# [ -8.0347, 10.8943],
# [ -1.7064, 9.8779],
# [ -2.2770, 11.1365],
# [ -3.4305, 18.9242],
# [ -3.7132, 28.6930],
# [-17.9371, 42.6237]], grad_fn=<AddmmBackward0>)
# 所以说这种输出的含义就是,它认为,属于1类别的概率是正数,2类别的概率甚至是个负数是吧...明白了;
# 可以这样理解。在这个输出中,每个子张量的第一个元素(正数)可以被视为模型预测该样本属于第一类别的
# 概率估计值,第二个元素(可能是负数)则是模型预测该样本属于第二类别的概率估计值。
# 需要注意的是,这里的数值本身并不一定直接对应严格意义上的概率,因为模型的输出可能
# 没有经过专门的归一化处理以确保和为 1,但通常可以相对地理解为表示某种倾向或可能性的大小。
# 而且负数在这种情况下也只是表示相对的大小关系,并不意味着真正的负概率。
# 在实际应用中,一般会通过合适的方法将这些值转换为更符合概率解释的形式。
print("==========probabilities:============")
probabilities = torch.softmax(outputs, dim=1)
print(probabilities)
# tensor([[1.0000e+00, 4.4273e-09],
# [1.0000e+00, 1.5222e-12],
# [1.0000e+00, 3.5589e-12],
# [1.0000e+00, 3.0917e-11],
# [1.0000e+00, 5.3411e-10],
# [1.0000e+00, 1.3765e-08],
# [1.0000e+00, 1.4835e-08],
# [1.0000e+00, 4.2492e-07],
# [1.0000e+00, 5.1067e-07],
# [9.9997e-01, 2.8726e-05],
# [5.4728e-06, 9.9999e-01],
# [5.5860e-08, 1.0000e+00],
# [3.0678e-19, 1.0000e+00],
# [9.8549e-08, 1.0000e+00],
# [9.0871e-08, 1.0000e+00],
# [4.0230e-06, 1.0000e+00],
# [4.5366e-06, 1.0000e+00],
# [9.9386e-07, 1.0000e+00],
# [5.5348e-12, 1.0000e+00],
# [1.3492e-18, 1.0000e+00]], grad_fn=<SoftmaxBackward0>)
#====================================================================================================
# 模型评估
eval_file_paths = ["traindata_c0_7.csv","traindata_c0_8.csv","traindata_c0_9.csv","traindata_c0_10.csv",
"traindata_c1_7.csv","traindata_c1_8.csv","traindata_c1_9.csv","traindata_c1_10.csv"
,"traindata_c1_21.csv","traindata_c1_22.csv","traindata_c1_23.csv"]
eval_data, eval_labels = load_data(eval_file_paths)
# 要保持原始张量的维度顺序不变,可以使用permute方法进行维度变换。
# permute方法接受一个参数,用于指定新的维度顺序。例如,如果你想将最后两维展平,可以使用以下代码:
# 上面说法根本就是错的,需要用到reshape方法,把张量reshape成一个[batch_size, in_features]的东西
num_of_eval_samples = eval_data.size(0)
new_eval_data_tensor = eval_data.reshape(num_of_eval_samples, 119*7)
print("new_eval_data_tensor shape:")
print(new_eval_data_tensor.shape) # 输出新张量的形状
# 评估模型
with torch.no_grad():
test_outputs = model(new_eval_data_tensor.to(torch.float32))
predicted_labels = torch.argmax(test_outputs, dim=1)
accuracy = (predicted_labels == eval_labels).sum().item() / eval_labels.size(0)
print("Accuracy:", accuracy)
print("==========评估阶段的predicted_labels:============")
print(predicted_labels)
print("==========评估阶段的eval_labels:============")
print(eval_labels)
print("==========评估阶段的probabilities:============")
probabilities = torch.softmax(test_outputs, dim=1)
print(probabilities)
# 假设已经训练好的模型为 model
torch.save(model.state_dict(), 'odel_weights.pth')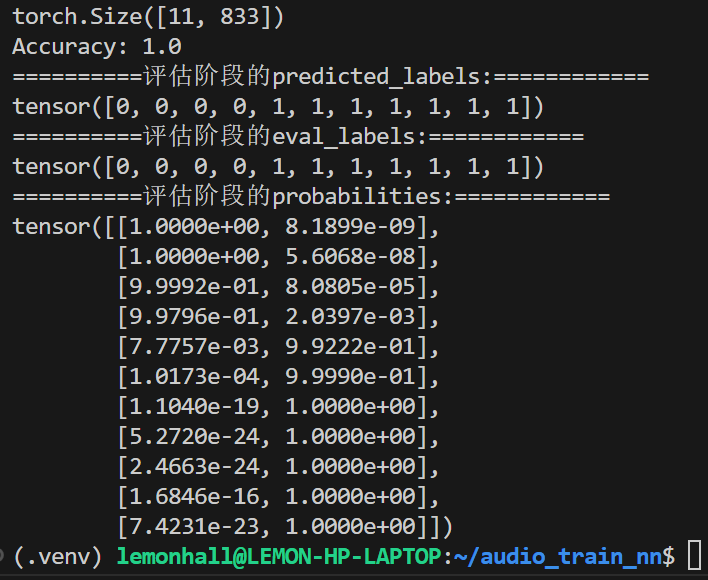
效果好到我都怀疑是过拟合
算是第一次成功吧,但因为esp32那边在wsl2下面没法打开COM5接口,实时得做pridict
所以我也很无奈,先这样吧,明后天把它先在电脑上跑起来
然后再移植到ESP32上去